En dan dit pleidooi (via Tim O'Reilly) voor links als first class object. Van Ian Bicking.
Doet denken aan de "smart pointers" indertijd om de persistency laag in OO min of meer transparant te maken.
maandag 29 december 2008
vrijdag 19 december 2008
REST en linking
vrijdag 12 december 2008
Een kritische noot
Een zekere Jeffrey Lindsay van een onderzoeksbedrijf Bernstein heeft een rapport geschreven waarin hij een paar kritische noten over SaaS en cloud computing maakt. Ik heb het rapport zelf niet gelezen, wel de samenvatting van Larry Dignan op ZDnet.
Kritiek is natuurlijk altijd welkom, maar dit is toch wel een beetje een raar verhaal. Als ik het goed begrijp, komt zijn kritiek op het volgende neer:
1. bedrijven doen het (cloud computing) nog niet of nauwelijks, want eigen machinerie is sneller, ze hebben geen zin om applicaties en documenten om te zetten, enz.
2. de leveranciers verdienen er ook weinig geld aan, zie Amazon dat (nog) niet erg veel geld genereert uit AWS. (Lindsay vermoedt dat Amazon het ook niet doet voor de revenuen, maar voor het imago, waardoor ze betere developers kunnen aantrekken, etc).
En de conclusie is dat het allemaal wel meevalt, en dat cloud computing wel gebruikt zal worden, maar beperkt en in een hybride model. Hij zeg bv dat Google Apps niet meer dan 10% van de MS office licenties af zal snoepen. (Dat is natuurlijk flauw, want naast Google Apps zijn er meer leveranciers van cloud-offices: ZoHo bijvoorbeeld, en ook MS zelf.)
Ik vind het een vreemd verhaal, want het lijkt alsof Lindsay de clou niet heeft begrepen. Inderdaad, cloud leveranciers verdienen niet ontzettend veel geld. En dat is niet alleen een aanloopverschijnsel, dat blijft zo. Gezien vanuit IT-leveranciers is dat natuurlijk raar, want waarom zou je er dan aan beginnen? Maar gezien vanuit de klanten betekent het dat de prijzen laag zijn en blijven, en dat cloud computing dus veel goedkoper is dan "eigen IT". En ja, het zal hier en daar wat minder makkelijk zzijn, en je moet documenten converteren, maar als je het niet doet, verlies je van de concurrent die wel overstapt op de cloud. Want het kostenvoordeel is gigantisch.
Dus op korte termijn zal hij wel gelijk hebben: bijna niemand stapt in één keer over, en vrijwel iedereen blijft voorlopig gedeeltelijk "eigen IT" gebruiken. Maar op wat langere termijn is de impact (waarschijnlijk, want ik heb d wijsheid ook niet in pacht) zeer groot. Niet alleen voor het goedkoper maken van bestaande produkten en diensten, maar vooral ook doordat hierdoor nieuwe produkten en diensten mogelijk worden, en ongetwijfeld, zoals dat gaat oude verdringen.
En wat betreft Amazon: ik ben ervan overtuigd dat AWS niet zomaar een aardigheidje is. Drie redenen:
1. Amazon kan hierdoor de voor het "oude bedrijf" benodigde capaciteit extra benutten en dus goedkoper maken.
2. Amazon leverde in feite voor derde partijen (tweede hands verkopers e.d.) eigenlijk al een click-in business model: niet alleen de catalogus, ook de betaalservice, soms delivery, enzovoort. AWS is een logische uitbreiding daarop.
3. Amazon zit voor wat betreft het "oude bedrijf" in de levering van content: boeken, muziek, enzovoort. Amazon ziet dat dat digitaliseert en via het net zal gaan. Vandaar de verkoop van MP3s, vandaar de Kindle. Maar daarvoor is een Web-infrastructuur nodig, en die is Amazon dan ook aan het opbouwen. Als je die ook door derden laat gebruiken, heb je AWS.
Allemaal logisch dus.
Kritiek is natuurlijk altijd welkom, maar dit is toch wel een beetje een raar verhaal. Als ik het goed begrijp, komt zijn kritiek op het volgende neer:
1. bedrijven doen het (cloud computing) nog niet of nauwelijks, want eigen machinerie is sneller, ze hebben geen zin om applicaties en documenten om te zetten, enz.
2. de leveranciers verdienen er ook weinig geld aan, zie Amazon dat (nog) niet erg veel geld genereert uit AWS. (Lindsay vermoedt dat Amazon het ook niet doet voor de revenuen, maar voor het imago, waardoor ze betere developers kunnen aantrekken, etc).
En de conclusie is dat het allemaal wel meevalt, en dat cloud computing wel gebruikt zal worden, maar beperkt en in een hybride model. Hij zeg bv dat Google Apps niet meer dan 10% van de MS office licenties af zal snoepen. (Dat is natuurlijk flauw, want naast Google Apps zijn er meer leveranciers van cloud-offices: ZoHo bijvoorbeeld, en ook MS zelf.)
Ik vind het een vreemd verhaal, want het lijkt alsof Lindsay de clou niet heeft begrepen. Inderdaad, cloud leveranciers verdienen niet ontzettend veel geld. En dat is niet alleen een aanloopverschijnsel, dat blijft zo. Gezien vanuit IT-leveranciers is dat natuurlijk raar, want waarom zou je er dan aan beginnen? Maar gezien vanuit de klanten betekent het dat de prijzen laag zijn en blijven, en dat cloud computing dus veel goedkoper is dan "eigen IT". En ja, het zal hier en daar wat minder makkelijk zzijn, en je moet documenten converteren, maar als je het niet doet, verlies je van de concurrent die wel overstapt op de cloud. Want het kostenvoordeel is gigantisch.
Dus op korte termijn zal hij wel gelijk hebben: bijna niemand stapt in één keer over, en vrijwel iedereen blijft voorlopig gedeeltelijk "eigen IT" gebruiken. Maar op wat langere termijn is de impact (waarschijnlijk, want ik heb d wijsheid ook niet in pacht) zeer groot. Niet alleen voor het goedkoper maken van bestaande produkten en diensten, maar vooral ook doordat hierdoor nieuwe produkten en diensten mogelijk worden, en ongetwijfeld, zoals dat gaat oude verdringen.
En wat betreft Amazon: ik ben ervan overtuigd dat AWS niet zomaar een aardigheidje is. Drie redenen:
1. Amazon kan hierdoor de voor het "oude bedrijf" benodigde capaciteit extra benutten en dus goedkoper maken.
2. Amazon leverde in feite voor derde partijen (tweede hands verkopers e.d.) eigenlijk al een click-in business model: niet alleen de catalogus, ook de betaalservice, soms delivery, enzovoort. AWS is een logische uitbreiding daarop.
3. Amazon zit voor wat betreft het "oude bedrijf" in de levering van content: boeken, muziek, enzovoort. Amazon ziet dat dat digitaliseert en via het net zal gaan. Vandaar de verkoop van MP3s, vandaar de Kindle. Maar daarvoor is een Web-infrastructuur nodig, en die is Amazon dan ook aan het opbouwen. Als je die ook door derden laat gebruiken, heb je AWS.
Allemaal logisch dus.
maandag 8 december 2008
Leonard Richardson over RESTful
donderdag 4 december 2008
Java en persistence frameworks
Commentaar is ook aardig, ookop de Serverside.
vrijdag 28 november 2008
Creatieve vernietiging
Voorpublicatie:
De Oostenrijks-Amerikaanse econoom Joseph Schumpeter heeft het begrip "creative destruction" geïntroduceerd. Dat hield in dat in een goed functionerende markteconomie steeds aan kapitaalvernietiging wordt gedaan, doordat bestaande bedrijven ter ziele gaan. Maar ze worden vervangen door nieuwe bedrijven die beter, sneller, efficiënter, goedkoper kunnen werken. Voor de bedrijven die verdwijnen is dat natuurlijk rampzalig, maar voor de samenleving als geheel is het juist goed: er treedt innovatie op, de productiviteit stijgt, en de welvaart neemt toe.
De neiging om bestaande bedrijven overeind te houden is dan ook weliswaar begrijpelijk, en voor de direct betrokkenen (eigenaars, werknemers, leveranciers) voordelig, maar op de wat langere duur desastreus. Immers, middelen die gestoken hadden kunnen worden in nieuwe welvaartsverhogende technieken en bedrijven, vloeien nu naar oude bedrijven die op den duur toch het loodje zullen leggen, en hoe dan ook minder produktief zijn dan de nieuwe bedrijven zouden zijn geweest.
Ik moet wel eens aan die "creative destruction" denken als ik deelneem aan de discussies over Service Oriented Architectures (SOA) en legacy integratie. Vaak wordt gezegd dat het mogelijk is om de investeringen in bestaande IT-systemen (de zogenaamde "legacy") te behouden, en toch die systemen op een flexibele wijze en via het web te kunnen gebruiken. Om dat te kunnen bereiken moet men dan een SOA inrichten, en daarbij een Enterprise Service Bus inrichten.
In de praktijk komt hier meestal weinig van terecht. Die SOA en ESB blijken erg ingewikkeld, en bovendien duur. En de voordelen van die "ontsluiting" van de legacy vallen vaak ook tegen, omdat die legacy zich helemaal niet goed als service laat ontsluiten, tenzij nog grotere investeringen worden gedaan.
En nu komen SaaS en cloud computing (ik zal het hierna op één hoop gooien onder de term "SaaS") om de hoek kijken. SaaS zet het business-model zoals dat tot nog toe in de IT opgeld deed op zijn kop. Je betaalt niet meer van te voren (voor een licentie of voor de bouw van maatwerk), maar voor het gebruik: per transactie, per gebruiker per maand, per opgeslagen MB. Standaardfunctionaliteit, afgerekend op gebruik. “Functionaliteit uit de muur”, zogezegd.
De voordelen zijn gigantisch: minder risico (want geen voorinvesteringen), meer mogelijkheden om van systeem of leverancier te veranderen, en vooral: lagere kosten.
Om deze voordelen te boeken moet je wel wat gangbare ideeën over IT overboord zetten. De kracht van SaaS zit in de standaardisatie. Je gaat dezelfde functionaliteit gebruiken als de buurman of concurrent die hetzelfde SaaS-systeem gebruikt. Voor gebruikers die nog leven met de illusie dat hun IT-systeem uniek is en een “strategisch voordeel” oplevert, is dat een forse stap. Aanpassen en customizen van SaaS kan meestal wel, maar is onverstandig. Het is toch weer een voorinvestering.
Ik hoor wel eens de tegenwerping: “Dan ben ik de greep op mijn IT kwijt!” Ja, dat is zo. Als je een blok aan je been kwijt bent, ben je de greep op dat blok kwijt.
Het is wel verstandig om te zorgen dat je niet met huid en haar aan de SaaS-leverancier bent overgeleverd. Dat kan door het maken van een model (een goed object- of datamodel is meestal voldoende) van de informatie die “uitbesteed” wordt. Dat model wordt geprojecteerd op het model van de leverancier, en door zo te werken is het mogelijk om betrekkelijk makkelijk gegevens te converteren, te up- en te downloaden, en dus ook van leverancier te wisselen.
En wat je vooral ook niet moet gaan proberen is de “integratie” van legacy “integreren” met SaaS. Natuurlijk, dat kan wel eens nodig zijn, maar je steeds moet heel goed kijken naar de alternatieven: gewoon niet integreren en los naast elkaar laten staan, of het legacy-systeem zelf ook vervangen door een SaaS-toepassing.
Want SaaS zal, denk ik, leiden tot de “creative destruction” van veel van de bestaande IT-systemen. Ze zullen worden vervangen door het gebruik van SaaS, wat veel goedkoper is, geen risico vormt, nauwelijks investeringen vergt, en de bedrijven niet meer vastklinkt aan enorme IT-systemen en de bijbehorende staf. Dat zal niet in één klap gaan. Sommige systemen zijn nog niet te vervangen, en sommige systemen misschien wel nooit.
Maar je moet wel bereid zijn om die “creative destruction” te laten gebeuren, en niet water in de wijn te doen door bestaande systemen nodeloos en tegen hoge kosten te integreren, en daarmee hun leven te verlengen. Want de concurrent die de radicale keuze maakt, heeft een groot kostenvoordeel, en dat zal op de markt te merken zijn.
De Oostenrijks-Amerikaanse econoom Joseph Schumpeter heeft het begrip "creative destruction" geïntroduceerd. Dat hield in dat in een goed functionerende markteconomie steeds aan kapitaalvernietiging wordt gedaan, doordat bestaande bedrijven ter ziele gaan. Maar ze worden vervangen door nieuwe bedrijven die beter, sneller, efficiënter, goedkoper kunnen werken. Voor de bedrijven die verdwijnen is dat natuurlijk rampzalig, maar voor de samenleving als geheel is het juist goed: er treedt innovatie op, de productiviteit stijgt, en de welvaart neemt toe.
De neiging om bestaande bedrijven overeind te houden is dan ook weliswaar begrijpelijk, en voor de direct betrokkenen (eigenaars, werknemers, leveranciers) voordelig, maar op de wat langere duur desastreus. Immers, middelen die gestoken hadden kunnen worden in nieuwe welvaartsverhogende technieken en bedrijven, vloeien nu naar oude bedrijven die op den duur toch het loodje zullen leggen, en hoe dan ook minder produktief zijn dan de nieuwe bedrijven zouden zijn geweest.
Ik moet wel eens aan die "creative destruction" denken als ik deelneem aan de discussies over Service Oriented Architectures (SOA) en legacy integratie. Vaak wordt gezegd dat het mogelijk is om de investeringen in bestaande IT-systemen (de zogenaamde "legacy") te behouden, en toch die systemen op een flexibele wijze en via het web te kunnen gebruiken. Om dat te kunnen bereiken moet men dan een SOA inrichten, en daarbij een Enterprise Service Bus inrichten.
In de praktijk komt hier meestal weinig van terecht. Die SOA en ESB blijken erg ingewikkeld, en bovendien duur. En de voordelen van die "ontsluiting" van de legacy vallen vaak ook tegen, omdat die legacy zich helemaal niet goed als service laat ontsluiten, tenzij nog grotere investeringen worden gedaan.
En nu komen SaaS en cloud computing (ik zal het hierna op één hoop gooien onder de term "SaaS") om de hoek kijken. SaaS zet het business-model zoals dat tot nog toe in de IT opgeld deed op zijn kop. Je betaalt niet meer van te voren (voor een licentie of voor de bouw van maatwerk), maar voor het gebruik: per transactie, per gebruiker per maand, per opgeslagen MB. Standaardfunctionaliteit, afgerekend op gebruik. “Functionaliteit uit de muur”, zogezegd.
De voordelen zijn gigantisch: minder risico (want geen voorinvesteringen), meer mogelijkheden om van systeem of leverancier te veranderen, en vooral: lagere kosten.
Om deze voordelen te boeken moet je wel wat gangbare ideeën over IT overboord zetten. De kracht van SaaS zit in de standaardisatie. Je gaat dezelfde functionaliteit gebruiken als de buurman of concurrent die hetzelfde SaaS-systeem gebruikt. Voor gebruikers die nog leven met de illusie dat hun IT-systeem uniek is en een “strategisch voordeel” oplevert, is dat een forse stap. Aanpassen en customizen van SaaS kan meestal wel, maar is onverstandig. Het is toch weer een voorinvestering.
Ik hoor wel eens de tegenwerping: “Dan ben ik de greep op mijn IT kwijt!” Ja, dat is zo. Als je een blok aan je been kwijt bent, ben je de greep op dat blok kwijt.
Het is wel verstandig om te zorgen dat je niet met huid en haar aan de SaaS-leverancier bent overgeleverd. Dat kan door het maken van een model (een goed object- of datamodel is meestal voldoende) van de informatie die “uitbesteed” wordt. Dat model wordt geprojecteerd op het model van de leverancier, en door zo te werken is het mogelijk om betrekkelijk makkelijk gegevens te converteren, te up- en te downloaden, en dus ook van leverancier te wisselen.
En wat je vooral ook niet moet gaan proberen is de “integratie” van legacy “integreren” met SaaS. Natuurlijk, dat kan wel eens nodig zijn, maar je steeds moet heel goed kijken naar de alternatieven: gewoon niet integreren en los naast elkaar laten staan, of het legacy-systeem zelf ook vervangen door een SaaS-toepassing.
Want SaaS zal, denk ik, leiden tot de “creative destruction” van veel van de bestaande IT-systemen. Ze zullen worden vervangen door het gebruik van SaaS, wat veel goedkoper is, geen risico vormt, nauwelijks investeringen vergt, en de bedrijven niet meer vastklinkt aan enorme IT-systemen en de bijbehorende staf. Dat zal niet in één klap gaan. Sommige systemen zijn nog niet te vervangen, en sommige systemen misschien wel nooit.
Maar je moet wel bereid zijn om die “creative destruction” te laten gebeuren, en niet water in de wijn te doen door bestaande systemen nodeloos en tegen hoge kosten te integreren, en daarmee hun leven te verlengen. Want de concurrent die de radicale keuze maakt, heeft een groot kostenvoordeel, en dat zal op de markt te merken zijn.
vrijdag 21 november 2008
SOA humor van Gartner
Lachen met Gartner. In ieder geval Frank Kenney heeft blijkbaar ook zijn vraagtekens bij de gangbare SOA.
Gartner, REST en WOA
Stefan Tilkov meldt dat Gartner de WOA (dat is ongeveer het zelfde als wat ik de ROA noem, geloof ik) omarmt. Hoera!
Is dus bij deze mainstream....
vrijdag 14 november 2008
Flex ipv Java?
Er is discussie over de vraag of Flex een goed alternatief is voor Java, voor programmering op de client (in RIA-omgevingen). Het zat er natuurlijk aan te komen....
woensdag 12 november 2008
dinsdag 11 november 2008
Consumentenmarkt en "zakelijke markt"
Phil Wainewright:
a. zakelijke markt en consumentenmarkt zijn niet (meer) van elkaar te scheiden
b. de consumentenmarkt is tegenwoordig meestal leidend als eht gaat om nieuwe applicaties, en wel hierom:
"So-called consumer applications are advancing faster because individuals have so much more compute resource available for their personal use, he pointed out, with high-spec multimedia PCs at home, iPhones in their pockets and so on. It struck me that this is an illuminating contrast to the previous generation of computing innovation, when it was enterprise professionals who had the budget freedom to purchase PCs and software packages like Lotus 1-2-3 and Microsoft Office, and who therefore led all the experimentation in the client-server software era.
Enterprise professionals in most corporations today are constrained by corporate purchasing policies and IT standardization (less so at Google, by the way, where employees can choose pretty much any personal compute device). But as individuals, those same people are not constrained by corporate risk assessment and compliance rules, while a decade or more of falling prices have brought today’s game-changing technologies into a consumer price bracket. "
Interessante observatie, al vraag ik me wel af of ie helemaal juist is. De Blackberry bijvoorbeeld is volgens mij een vrijwel alleen zakelijk verkocht apparaat, in ieder geval in Nederland.
Maar in het algemeen klopt het wel, denk ik.
Enterprise professionals in most corporations today are constrained by corporate purchasing policies and IT standardization (less so at Google, by the way, where employees can choose pretty much any personal compute device). But as individuals, those same people are not constrained by corporate risk assessment and compliance rules, while a decade or more of falling prices have brought today’s game-changing technologies into a consumer price bracket. "
Interessante observatie, al vraag ik me wel af of ie helemaal juist is. De Blackberry bijvoorbeeld is volgens mij een vrijwel alleen zakelijk verkocht apparaat, in ieder geval in Nederland.
Maar in het algemeen klopt het wel, denk ik.
maandag 3 november 2008
vrijdag 31 oktober 2008
REST 2
(Dit is ook een test om te kijken of de twitterfeed werkt).
Wat betreft die duistere passage in die post van mark Littke waarover ik gisteren schreef: ik denk dat hij bedoelt dat de te navigeren paden in de resource structuur duidelijk moeten zijn in de representatie die de client terugkrijgt. Een domeinspecifiek object- of datamodel is prima, maar mag niet impliciet zijn, dat wil zeggen: het moet niet nodig zijn dat de client developer a priori weet hoe het "model" in mekaar zit.
donderdag 30 oktober 2008
REST
Stuk van Mark Little op InfoQ, waarin de hele tijd Roy Fileding wordt aangehaald.
Hmmmm....
Wat bv te denken van:
A REST API must not define fixed resource names or hierarchies. Servers must have the freedom to control their own namespace. Instead, allow servers to instruct clients on how to construct appropriate URIs, such as is done in HTML forms and URI templates, by defining those instructions within media types and link relations. [Failure here implies that clients are assuming a resource structure due to out-of band information, such as a domain-specific standard, which is the data-oriented equivalent to RPC's functional coupling]."
Vooral dat stuk tussen die haken, over die resource structuur: ik weet niet zeker of ik he daar wel mee eens ben. Ik ben wel voor die resource structures.
dinsdag 28 oktober 2008
Microsoft Azure
Microsoft heeft Azure aangekondigd. Azure is de cloud van Microsoft. Ziet er interessant uit, vooral ook omdat MS nogal inzet op Model-Driven approaches, met name het Oslo-verhaal.
Dat is potentieel een zeer interessante combinatie: Oslo + Azure. Daar zit in ieder geval ik wel op te wachten,
Dat is potentieel een zeer interessante combinatie: Oslo + Azure. Daar zit in ieder geval ik wel op te wachten,
donderdag 23 oktober 2008
AWS gaat nu echt los, geloof ik
AWS (Amazon Web Services) gaan nu echt los. Er is nu een SLA (99.95% of zo uptime), EC2 is uit beta, er is een Windows image, er komen allerlei consoles, load balancing is verbeterd, en Vogels deelt mede dat Amazon nu ook grote bedrijven als doelgroep heeft.
Tot nog toe zat er wat hobbyistisch aan, maar dat gaat er af.
Ik zit zelf ook met interesse te kijken naar de ElasticFox plug in voor FireFox, die het mogelijk maakt de EC2 image te sturen vanuit de browser.
Tot nog toe zat er wat hobbyistisch aan, maar dat gaat er af.
Ik zit zelf ook met interesse te kijken naar de ElasticFox plug in voor FireFox, die het mogelijk maakt de EC2 image te sturen vanuit de browser.
dinsdag 21 oktober 2008
Silver Bullit revisited
Ik vond deze samenvatting van een panel op OOPSLA. Panels zijn meestal geouwehoer, maar dit is wel aardig, en stipt nogal wat vragen aan waarmee ik mij ook bezighoudt. Bijvoorbeeld Dave Thomas:
"1. People have a “very natural tendency to look for easy answers to hard questions, designing software is hard and it will always be hard.”
2. New technologies are often over-hyped: “they have to kind of paint it as a silver bullet because otherwise people won’t listen.”
3. Desire for people to seek better tools rather than “actually learning the trade.” Dave used the metaphor: “there is an old saying: ‘the poor
workman blames his tools’ - people are poor wfor silver bullets to avoid learning the trade. "
2. New technologies are often over-hyped: “they have to kind of paint it as a silver bullet because otherwise people won’t listen.”
3. Desire for people to seek better tools rather than “actually learning the trade.” Dave used the metaphor: “there is an old saying: ‘the poor
workman blames his tools’ - people are poor wfor silver bullets to avoid learning the trade. "
donderdag 16 oktober 2008
REST modellering
Hoe kun je een RESTful architectuur modelleren? Met andere woorden: hoe modelleer je resources?
Het belangrijkste punt is dat men zich realiseert dat een resource iets wezenlijk anders is dan een component in de gebruikelijke zin van het woord, en in zeker opzicht ook dan een object. Want componenten worden ontworpen vanuit het beginsel van "information-hiding", en bij objecten zijn we oo kgewend dat te doen. Componenten en objecten stellen aan de buitenkant alleen een interface ter beschikking. De interne gegevens zijn verborgen, evenals de methods. En zowel componenten als objecten schermen het woud van componenten resp. objecten "achter zich" af. In feite zijn ze allemaal Facades (het GoF-pattern). De Law of Demeter schreef voor dat een object niet zomaar referenties naar "achterliggende" objecten mag verschaffen.
Met resources ligt dat iets anders. Ja, je kunt resources zo ontwerpen dat het in feite ook facades zijn, en zo dat ze hun interne informatie volledig verbergen. (Al zal dat leiden tot nogal overladen POST-methods.) Maar resources zijn (ook) "knopen" op het web, en zijn juist bedoeld om navigatie naar achterliggende "knopen" (resources dus) mogelijk te maken.
Bij een (goed ontworpen) object-model is dat trouwens ook zo. Dat is wel degelijk bedoeld om transparant te zijn. En dat is dus een goed begin voor een resource-model.
Dit leidt tot de volgende werkwijze:
1. maak een object-model voor het domein, bij voorkeur met standaard-analysepatronen, bijvoorbeeld door de colors-aanpak te gebruiken.
2. onderzoek welke objecten die in het model worden beschreven resources gaan worden. (In de praktijk zullen ze dat allemaal worden.)
3. maak een pad-onafhankelijke identificatie van die objecten. Bijvoorbeeld: .../{Class}/{object-id}, dus: http://JansenBV.nl/Order/id=12345
4. Onderzoek welke "paden" in het object-model navigeerbaar moeten zijn, en welk deel van het model "publiek" is. Hierop wordt de GET-URI-structuur ontworpen.
(In de praktijk zullen associaties en aggregaties in het model vrijwel altijd "publiek" zijn. Met composities ligt het iets ingewikkelder. Die kunnen "verborgen" zijn. Het is een optie om voor het resource-model een speciale modelvorm (UML Profile?) te maken waarbij de betekenis van de object-relaties (associatie, aggregatie, compositie) op die manier is gedefinieerd.)
5. Onderzoek welke messages (maw: methods aangeroepen door een bepaald object) creatie of deletie (zal wel geen nederlands zijn; bij deze) van een object of wijziging van een attribuut tot gevolg heeft. Hierop moet de PUT/DELETE-structuur worden gedefinieerd.
6. Onderzoek wat er overblijft aan "gedrag" in het model wat niet wordt gedekt doro de GETs, PUTs en DELETEs. Daarvoor worden POSTs ontworpen.
Dit is een begin.
Het belangrijkste punt is dat men zich realiseert dat een resource iets wezenlijk anders is dan een component in de gebruikelijke zin van het woord, en in zeker opzicht ook dan een object. Want componenten worden ontworpen vanuit het beginsel van "information-hiding", en bij objecten zijn we oo kgewend dat te doen. Componenten en objecten stellen aan de buitenkant alleen een interface ter beschikking. De interne gegevens zijn verborgen, evenals de methods. En zowel componenten als objecten schermen het woud van componenten resp. objecten "achter zich" af. In feite zijn ze allemaal Facades (het GoF-pattern). De Law of Demeter schreef voor dat een object niet zomaar referenties naar "achterliggende" objecten mag verschaffen.
Met resources ligt dat iets anders. Ja, je kunt resources zo ontwerpen dat het in feite ook facades zijn, en zo dat ze hun interne informatie volledig verbergen. (Al zal dat leiden tot nogal overladen POST-methods.) Maar resources zijn (ook) "knopen" op het web, en zijn juist bedoeld om navigatie naar achterliggende "knopen" (resources dus) mogelijk te maken.
Bij een (goed ontworpen) object-model is dat trouwens ook zo. Dat is wel degelijk bedoeld om transparant te zijn. En dat is dus een goed begin voor een resource-model.
Dit leidt tot de volgende werkwijze:
1. maak een object-model voor het domein, bij voorkeur met standaard-analysepatronen, bijvoorbeeld door de colors-aanpak te gebruiken.
2. onderzoek welke objecten die in het model worden beschreven resources gaan worden. (In de praktijk zullen ze dat allemaal worden.)
3. maak een pad-onafhankelijke identificatie van die objecten. Bijvoorbeeld: .../{Class}/{object-id}, dus: http://JansenBV.nl/Order/id=12345
4. Onderzoek welke "paden" in het object-model navigeerbaar moeten zijn, en welk deel van het model "publiek" is. Hierop wordt de GET-URI-structuur ontworpen.
(In de praktijk zullen associaties en aggregaties in het model vrijwel altijd "publiek" zijn. Met composities ligt het iets ingewikkelder. Die kunnen "verborgen" zijn. Het is een optie om voor het resource-model een speciale modelvorm (UML Profile?) te maken waarbij de betekenis van de object-relaties (associatie, aggregatie, compositie) op die manier is gedefinieerd.)
5. Onderzoek welke messages (maw: methods aangeroepen door een bepaald object) creatie of deletie (zal wel geen nederlands zijn; bij deze) van een object of wijziging van een attribuut tot gevolg heeft. Hierop moet de PUT/DELETE-structuur worden gedefinieerd.
6. Onderzoek wat er overblijft aan "gedrag" in het model wat niet wordt gedekt doro de GETs, PUTs en DELETEs. Daarvoor worden POSTs ontworpen.
Dit is een begin.
woensdag 15 oktober 2008
Elbot en de Turing-test
http://www.elbot.com/
Dat is Elbot, een robot die er dit jaar heel dicht bij kwam om de Turing test te breken.
Je kunt met Elbot praten, en het lijkt heel erg op een conversatie met mijn broer Kees.
Dat is Elbot, een robot die er dit jaar heel dicht bij kwam om de Turing test te breken.
Je kunt met Elbot praten, en het lijkt heel erg op een conversatie met mijn broer Kees.
woensdag 1 oktober 2008
Microsoft in Amazon's cloud
maandag 29 september 2008
SOA: hoe in te voeren? (2)
Rik schrijft:
"ESB gedreven SOA". Bestaat er dan ook zoiets als "niet ESB gedreven SOA"? Volgens mij niet. Zelfs in een volledig geharmoniseerde en gestandardiseerde wereld zul je altijd berichten moeten routeren, gegarandeerd moeten transporteren en moeten orkesteren. Of zie jij een alternatief?
Ja, ik zie wel een alternatief.
Natuurlijk, dat routeren, transporteren, enzovoort is nodig. Maar is het nodig dat allemaal te integreren in één tool, namelijk de ESB? Die is duur om aan te schaffen, duur om te implementeren, en bovendien proprietary, wat in feite betekent dat het bedrijf in kwestie zich min of meer uitlevert aan de vendor.
Bovendien zijn heel veel van die "luxe" functionaliteiten van een ESB helemaal niet zo hard nodig, en worden ze zelden gebruikt.
Door dit alles worden die ESB-implementaties noodzakelijkerwijs company-brede projecten, en zoals we allemaal weten: die mislukken, zeker als ze niet 100% nodig zijn. En dat zijn die ESB-projecten niet, omdat er altijd een plan B is: een beetje halfwas invoeren, en de rest naar de toekomst schuiven. En plan C is: installeren, roepen dat je het gebruikt, maar in werkelijkheid gewoon de ouwe trouwe messagebroker blijven gebruiken.
Ik zie zeker twee alternatieven.
1. gebruik een mean&lean "ESB" voor de routering etc van het berichtenverkeer, en gebruik daarvan de functionaliteit op een dusdanige wijze dat je kunt switchen naar een ander tool. Een manier om dat te doen, is het gebruik van meer dan één ESB, maar dat stuit uiteraard nog wel eens op investeringsgrenzen.
2. gebruik een REST-route, en ga naar een ROA-architectuur. Dat kan ook, daar is nauwelijks extra tooling voor nodig, en kan incrementeel worden gedaan. Maar het sluit (in ieder geval op het eerste gezicht) veel minder goed aan bij de bestaande architectuur, en bovendien weten systeemarchitecten e.d. nit hoe ze dit moeten aanpakken.
Een extra argument voor deze alternatieve routes is dat de ver-SaaS-ing of ver-cloud-ing van de functionaliteit eraan komt, en dan zit een zware proprietary ESB ontzettend in de weg, zowel technisch als budgettair.
Niet doen dus, het zijn dinosaurussen.
"ESB gedreven SOA". Bestaat er dan ook zoiets als "niet ESB gedreven SOA"? Volgens mij niet. Zelfs in een volledig geharmoniseerde en gestandardiseerde wereld zul je altijd berichten moeten routeren, gegarandeerd moeten transporteren en moeten orkesteren. Of zie jij een alternatief?
Ja, ik zie wel een alternatief.
Natuurlijk, dat routeren, transporteren, enzovoort is nodig. Maar is het nodig dat allemaal te integreren in één tool, namelijk de ESB? Die is duur om aan te schaffen, duur om te implementeren, en bovendien proprietary, wat in feite betekent dat het bedrijf in kwestie zich min of meer uitlevert aan de vendor.
Bovendien zijn heel veel van die "luxe" functionaliteiten van een ESB helemaal niet zo hard nodig, en worden ze zelden gebruikt.
Door dit alles worden die ESB-implementaties noodzakelijkerwijs company-brede projecten, en zoals we allemaal weten: die mislukken, zeker als ze niet 100% nodig zijn. En dat zijn die ESB-projecten niet, omdat er altijd een plan B is: een beetje halfwas invoeren, en de rest naar de toekomst schuiven. En plan C is: installeren, roepen dat je het gebruikt, maar in werkelijkheid gewoon de ouwe trouwe messagebroker blijven gebruiken.
Ik zie zeker twee alternatieven.
1. gebruik een mean&lean "ESB" voor de routering etc van het berichtenverkeer, en gebruik daarvan de functionaliteit op een dusdanige wijze dat je kunt switchen naar een ander tool. Een manier om dat te doen, is het gebruik van meer dan één ESB, maar dat stuit uiteraard nog wel eens op investeringsgrenzen.
2. gebruik een REST-route, en ga naar een ROA-architectuur. Dat kan ook, daar is nauwelijks extra tooling voor nodig, en kan incrementeel worden gedaan. Maar het sluit (in ieder geval op het eerste gezicht) veel minder goed aan bij de bestaande architectuur, en bovendien weten systeemarchitecten e.d. nit hoe ze dit moeten aanpakken.
Een extra argument voor deze alternatieve routes is dat de ver-SaaS-ing of ver-cloud-ing van de functionaliteit eraan komt, en dan zit een zware proprietary ESB ontzettend in de weg, zowel technisch als budgettair.
Niet doen dus, het zijn dinosaurussen.
vrijdag 26 september 2008
SOA: hoe in te voeren?
Jonathan Mack op InfoQ, over hoe moeilijk het is om SOA in te voeren.
"When it comes to the SOA roadmap, the two most popular approaches to SOA implementation have emerged lately:
"...to build SOA incrementally. Most vendors have come around to recognizing that this is the most reasonable approach. Nevertheless, it’s not simple to accomplish. The key elements of an Enterprise Server Bus (ESB) - the ability to translate and transform information from one system to another and the ability to route messages - as well as the messaging infrastructure to transmit the information must be in place from the beginning. Common (shared) services such as logging, monitoring, and exception handling also should be Day 1 implementations."
Ja, zo ken ik er ook nog wel een paar. Dit is dus ook een moeizaam verhaal.
Conclusie: SOA, althans ESB gedreven SOA, werkt niet.
Misschien wat kort door de bocht, maar eigenlijk komt het daar wel op neer. Zie ook dit en dit.
"When it comes to the SOA roadmap, the two most popular approaches to SOA implementation have emerged lately:
- Enterprise (top-down) SOA approach, which is an extremely high - risk approach with an initial price tag of a several million dollars. In addition, based on the size and complexity, such project can virtually never be accurately estimated.
- Grassroots (bottom-up) SOA approach - implementing elements of SOA (both services and infrastructure) as parts of existing business-driven IT undertaking. This approach typically does not succeed. On one hand, the scope of resulting services is limited to the specific business problem and might not be applicable (or even wrong) for the rest of enterprise. On another hand, the time and expense required to build the SOA layer can detract from other business needs of a project."
"...to build SOA incrementally. Most vendors have come around to recognizing that this is the most reasonable approach. Nevertheless, it’s not simple to accomplish. The key elements of an Enterprise Server Bus (ESB) - the ability to translate and transform information from one system to another and the ability to route messages - as well as the messaging infrastructure to transmit the information must be in place from the beginning. Common (shared) services such as logging, monitoring, and exception handling also should be Day 1 implementations."
Ja, zo ken ik er ook nog wel een paar. Dit is dus ook een moeizaam verhaal.
Conclusie: SOA, althans ESB gedreven SOA, werkt niet.
Misschien wat kort door de bocht, maar eigenlijk komt het daar wel op neer. Zie ook dit en dit.
vrijdag 19 september 2008
O'Reilly gelooft ook niet in het advertentie-model
donderdag 18 september 2008
Content delivery door Amazon AWS
Kijk, dit zat er in: content delevery via één API door AWS. Koppeling met het betaalsysteem FPS ligt natuurlijk vreselijk voor de hand.
Zie AWS blog en Werner Vogels.
maandag 15 september 2008
Google op zee
Google wil datacenters op zee. Om de golfenergie te gebruiken. En om minder belastingen te betalen. En misschien ook wel om minder last van wetten en regels en juridisch gezeur te hebben.
Onzin over cloud computing
De laatste tijd lees ik nogal eens van die verhalen waarin wordt gezegd da cloud computing er niet is of komt, omdat er nog steeds on-premise computing is en blijft. Staat op mijn lijstje om eens op te reageren, maar Anshu Sharma heeft het al gedaan. Hij heeft groot gelijk.
donderdag 4 september 2008
SaaS lock-in: een risico?
Vendor lock-in bij SaaS-oplossingen wordt de laatste tijd nogal eens als risico van SaaS geschetst. Terecht, want lock-in is altijd een probleem, bij een pakket, bij SaaS, en ook bij zelfgebouwde oplossingen.
Maar het lock-in risico bij SaaS wordt overdreven. Wel gelden vier regels:
1. Kies alleen SaaS-oplossingen waarbij je ondubbelzinnig eigenaar van de data bent en blijft.
2. Zorg voor een model (bijvoorbeeld een objectmodel) waarin de business beschreven is, en projecteer dat op het model van de leverancier. Dit is nodig voor conversies, voor koppelingen en voor de exit-strategie.
3. Kies alleen SaaS-oplossingen met goede interfaces. Niet alleen user-interfaces, maar ook APIs voor data-verkeer en integratie.
4. Gebruik die APIs vervolgens zo min mogelijk. De kracht van SaaS zit vooral in de lage kosten en investeringen. Gooi dat voordeel niet weg door niet echt noodzakelijke integratie zelf te bouwen, want daarmee lockt u uzelf in.
Kortom: lock-in is een beheersbaar risico. En de Pavlov-reactie van IT-ers om dan maar zelf iets te gaan bouwen, maakt het erger. Misschien wordt de vendor lock-in iets minder, maar de maatwerk lock-in wordt des te groter.
Maar het lock-in risico bij SaaS wordt overdreven. Wel gelden vier regels:
1. Kies alleen SaaS-oplossingen waarbij je ondubbelzinnig eigenaar van de data bent en blijft.
2. Zorg voor een model (bijvoorbeeld een objectmodel) waarin de business beschreven is, en projecteer dat op het model van de leverancier. Dit is nodig voor conversies, voor koppelingen en voor de exit-strategie.
3. Kies alleen SaaS-oplossingen met goede interfaces. Niet alleen user-interfaces, maar ook APIs voor data-verkeer en integratie.
4. Gebruik die APIs vervolgens zo min mogelijk. De kracht van SaaS zit vooral in de lage kosten en investeringen. Gooi dat voordeel niet weg door niet echt noodzakelijke integratie zelf te bouwen, want daarmee lockt u uzelf in.
Kortom: lock-in is een beheersbaar risico. En de Pavlov-reactie van IT-ers om dan maar zelf iets te gaan bouwen, maakt het erger. Misschien wordt de vendor lock-in iets minder, maar de maatwerk lock-in wordt des te groter.
woensdag 3 september 2008
Cloud browser
Google heeft Chrome uitgebracht, in beta. Chrome is een webbrowser, op het eerste gezicht een concurrent van Firefox, IE, Safari, Opera, etc. Maar er is een verschil: Chrome is vooral gericht op het ondersteunen van het runnen van webapplicaties.
En ik denk dat het Google niet zozeer gaat om het van de markt drukken van IE of zo, maar om het versnellen van het gebruik van webapps.
En ik denk dat het Google niet zozeer gaat om het van de markt drukken van IE of zo, maar om het versnellen van het gebruik van webapps.
donderdag 28 augustus 2008
voor de restliefhebbers
Dit verhaal van Bill de hÒra (daar heb ik dus het character palette bij nodig). En ook deze.
Zijn punt: REST is niet makkelijk, maar het kan in ieder geval de vereiste complexiteit aan. Dit in tegenstelling tot SOAP etc.
Dat laatste punt is wel waar: SOAP is inderdaad heel erg simpel, maar het lsot ook vrijwel niets op.
UML + DSL
Dit is een interessante ontwikkeling. Microsoft gaat toch iets met UML doen, en zelfs op een hoger abstractie-nivo dan de DSLs.
Ik kan me daar wel iets bij voorstellen (itt Steven Kelly), maar ik moet toch eerst even zien hoe dit werkt.
(via Jacob den Haan)
donderdag 21 augustus 2008
MDE en de silver bullit
Johan den Haan heeft de moeite genomen op mijn vorige post te reageren, en daar ben ik blij mee.
Hij schrijft:
"Ik denk zeker dat MDE de toekomst is. Waar ik voor pleit, wat ook in het InfoQ artikel naar voren komt, is een bredere aanpak dan alleen MDA of alleen DSLs. MDE , met DSLs als basis, heeft meer potentie. "
Ik ben het met hem eens. Wellicht zie ik meer in archtype domein modellen dan Johan, en Johan weer wat meer in "echte" DSLs, maar dat zijn minieme verschillen van inzicht. Dat gaat vooral over welke vorm een DSL moet of kan hebben, en hoe een DSL in MDE kan worden gebruikt.
Johan verder:
"Waar ik sceptisch over ben is alles wat model-driven in de naam heeft te zien als 'silver bullet'. Daarnaast denk ik dat het opzetten van een model gedreven ontwikkelstraat om enorm veel expertise vraagt, zowel op het gebied van software engineering als op het gebied van language engineering."
Inderdaad, silver bullets bestaan niet. En wat betreft die model driven ontwikkelstraat (ik ben wat minder scrupuleus als het gaat om het mengen van nederlands en engels, geloof ik :) ): inderdaad, dat is een probleem. Misschien is het zelfs wel een onmogelijke opgave.
Want om MDE (in ieder geval zoals ik dat zie) goed aan de praat te krijgen, moet aan een aantal voorwaarden zijn voldaan:
1. de generatie van executables (al of niet met leesbare code als tussenstation) moet 100% zijn. Zodra een aspect van een domein of architectuur op twee plaatsen in de stroom (bijvoorbeeld in een model en in programmacode) moet worden bewerkt, zal na verloop van tijd de bewerking alleen nog op de tweede plaats (stroomafwaarts dus) worden onderhouden. Het model wordt waardeloos en de model driven straat ook.
2. de MDE straat moet complexe domeinen aankunnen, en ook voldoende vrijheidsgraden bieden om hybride architcturen, verscheidene platforms, etc, etc aan te kunnen.
Deze twee punten vereisen dus een grote en ingewikkelde ontwikkelstraat, hoogstwaarschijnlijk slechts te bedienen door lieden die buitengewoon goed weten hoe het werkt, hoet zou moeten werken, enzovoort. Experts dus.
Maar om een aanpak als MDE (of welke nieuwe aanpak of tool voor software-ontwikkeling dan ook) met succes geïntroduceerd en geaccepteerd te krijgen, zijn er nog een paar voorwaarden:
3. de aanpak en de tooling moet redelijk bestand zijn tegen onoordeelkundig gebruik. Met andere woorden: een "foute" aanpak moet òf onmogelijk zijn, òf niet tot desastreuze resultaten leiden.
4. aanpak en werkwijze moeten te leren zijn door "gewone" software-ontwikkelaars. Liefst in een training van maximaal 5 dagen.
Vernieuwingen die een enorme expertise, training en discipline vereisen hebben de neiging te mislukken, zeker als de betrokkenen menen een simpeler alternatief (i.c. de conventionele werkwijze) te hebben. Dat laat de geschiedenis van de software-ontwikkeling volgens mij zien.
Het is duidelijk: voorwaarde 1 en 2 staan op zeer gespannen voet met 3 en 4. Ze zijn nauwelijks te combineren.
De conclusie:
MDE is alleen goed te gebruiken in situaties waarin de complexiteit van de opdracht, de vereiste snelheid van ontwikkeling, etc een aanpak als MDE noodzakelijk maakt. En de organisatie moet de consequenties (kosten tooling, eisen aan de experts, etc) dan voor lief nemen en niet toch een ogenschijnlijk goedkopere combinatie met een conventionele aanpak na te streven (met kletspraat over win-win-situaties enzo).
"Gewone" systeemontwikkeling voldoet hier maar zelden aan, dat is duidelijk. Grootschalige systeemontwikkeling, speciaal bij produktontwikkeling (product line engineering), daarentegen bieden wel mogelijkheden. En een van de effecten van SaaS en cloud computing zal zijn dat meer software op die manier gemaakt en onderhouden zal worden. Maar in de gewone systeemontwikkeling zie ik niet veel ruimte voor MDE.
Ben ik nou te cynisch?
Hij schrijft:
"Ik denk zeker dat MDE de toekomst is. Waar ik voor pleit, wat ook in het InfoQ artikel naar voren komt, is een bredere aanpak dan alleen MDA of alleen DSLs. MDE , met DSLs als basis, heeft meer potentie. "
Ik ben het met hem eens. Wellicht zie ik meer in archtype domein modellen dan Johan, en Johan weer wat meer in "echte" DSLs, maar dat zijn minieme verschillen van inzicht. Dat gaat vooral over welke vorm een DSL moet of kan hebben, en hoe een DSL in MDE kan worden gebruikt.
Johan verder:
"Waar ik sceptisch over ben is alles wat model-driven in de naam heeft te zien als 'silver bullet'. Daarnaast denk ik dat het opzetten van een model gedreven ontwikkelstraat om enorm veel expertise vraagt, zowel op het gebied van software engineering als op het gebied van language engineering."
Inderdaad, silver bullets bestaan niet. En wat betreft die model driven ontwikkelstraat (ik ben wat minder scrupuleus als het gaat om het mengen van nederlands en engels, geloof ik :) ): inderdaad, dat is een probleem. Misschien is het zelfs wel een onmogelijke opgave.
Want om MDE (in ieder geval zoals ik dat zie) goed aan de praat te krijgen, moet aan een aantal voorwaarden zijn voldaan:
1. de generatie van executables (al of niet met leesbare code als tussenstation) moet 100% zijn. Zodra een aspect van een domein of architectuur op twee plaatsen in de stroom (bijvoorbeeld in een model en in programmacode) moet worden bewerkt, zal na verloop van tijd de bewerking alleen nog op de tweede plaats (stroomafwaarts dus) worden onderhouden. Het model wordt waardeloos en de model driven straat ook.
2. de MDE straat moet complexe domeinen aankunnen, en ook voldoende vrijheidsgraden bieden om hybride architcturen, verscheidene platforms, etc, etc aan te kunnen.
Deze twee punten vereisen dus een grote en ingewikkelde ontwikkelstraat, hoogstwaarschijnlijk slechts te bedienen door lieden die buitengewoon goed weten hoe het werkt, hoet zou moeten werken, enzovoort. Experts dus.
Maar om een aanpak als MDE (of welke nieuwe aanpak of tool voor software-ontwikkeling dan ook) met succes geïntroduceerd en geaccepteerd te krijgen, zijn er nog een paar voorwaarden:
3. de aanpak en de tooling moet redelijk bestand zijn tegen onoordeelkundig gebruik. Met andere woorden: een "foute" aanpak moet òf onmogelijk zijn, òf niet tot desastreuze resultaten leiden.
4. aanpak en werkwijze moeten te leren zijn door "gewone" software-ontwikkelaars. Liefst in een training van maximaal 5 dagen.
Vernieuwingen die een enorme expertise, training en discipline vereisen hebben de neiging te mislukken, zeker als de betrokkenen menen een simpeler alternatief (i.c. de conventionele werkwijze) te hebben. Dat laat de geschiedenis van de software-ontwikkeling volgens mij zien.
Het is duidelijk: voorwaarde 1 en 2 staan op zeer gespannen voet met 3 en 4. Ze zijn nauwelijks te combineren.
De conclusie:
MDE is alleen goed te gebruiken in situaties waarin de complexiteit van de opdracht, de vereiste snelheid van ontwikkeling, etc een aanpak als MDE noodzakelijk maakt. En de organisatie moet de consequenties (kosten tooling, eisen aan de experts, etc) dan voor lief nemen en niet toch een ogenschijnlijk goedkopere combinatie met een conventionele aanpak na te streven (met kletspraat over win-win-situaties enzo).
"Gewone" systeemontwikkeling voldoet hier maar zelden aan, dat is duidelijk. Grootschalige systeemontwikkeling, speciaal bij produktontwikkeling (product line engineering), daarentegen bieden wel mogelijkheden. En een van de effecten van SaaS en cloud computing zal zijn dat meer software op die manier gemaakt en onderhouden zal worden. Maar in de gewone systeemontwikkeling zie ik niet veel ruimte voor MDE.
Ben ik nou te cynisch?
donderdag 14 augustus 2008
Waarom MDE zal falen volgens Johan den Haan
Op InfoQ trof ik dit artikel aan: 8 redenen waarom MDE zal falen. MDE falen? 8 redenen maar liefst?! Hoog te paard ging ik het stuk lezen, maar het is eigenlijk een vrij goed verhaal. De schrijver, Johan den Haan, weet waarover hij praat, en zijn opmerkingen zijn blijkbaar (mede) ingegeven door praktische ervaring.
De 8 redenen zijn ook meer 8 grote risico's, en in zijn schets daarvan heeft hij wel gelijk. Ik zal ze even nalopen.
1. De gangbare MDE-aanpakken en -tools zijn vrijwel uitsluitend gericht op het korte termijn doel van verhoging van produktiviteit voor developers: meer functiepunten per uur, en verder niks.
Ja, dat is zo, en dat is inderdaad een van de grote tekortkomingen van de gebruikelijke aanpakken. Links laten liggen dus, en richten op waar het in MDE echt over gaat (vorige week blogde ik daarover ook al).
2. in MDE concentreert men zich meestal op slechts één modelleringsdimensie. Architectuur bijvoorbeeld wordt er bij de MDA aanpak een beetje bijgefrommeld in de PSM.
Inderdaad, dat lijkt nergens op. Den Haan is hier nog veel te voorzichtig: je hebt zowel binnen het domein als binnen de weergave van de technische architectuur en implementatie verscheidene modelleringsdimensies nodig.
Naar mijn idee is dat te doen met een goede modeltransformatieaanpak, maar simpel is het niet. Bovendien: hoeveel modeldimensies moeten we aankunnen?
3. de gangbare tools richten zich op het maken van nieuwe artefacten (stukken code, getransformeerde modellen, etc) en laten de problemen van aanpassing van bestaande artefacten links liggen.
Den Haan heeft hier ongetwijfeld gelijk, maar ik denk dat hij hier de zaak wat complexer maakt dan strikt nodig is. Immers, als je afgeleide artefacten 100% kunt genereren, kun je ook zelfs voor een kleine wijziging de hele zwik van (tussen)modellen, code, enzovoort gewoon opnieuw maken. Daar zitten nadelen en beperkingen aan (zoals de veteranen uit de CBD-hoek weten), maar je komt er wel een eind mee.
4. MDE richt zich teveel op General Purpose Languages zoals UML. Dat is niet voldoende: je hebt voor deelterreinen specifieke talen nodig. Het bekende DSL-lied.
Ja, dat is zo, maar ik denk wel dat in ieder geval als het gaat om business domeinen de combinatie van "gewoon" UML, analyse patronen (archetypes) en een abstractiemechanisme waarmee specifieke modellen van meer generieke patronen kunnen worden afgeleid heel veel helpt. Je kunt dan natuurlijk zo'n analyse-patroon of een bepaalde afleiding als een DSL zien.
Zie ook hier en hier en hier.
5. Zelf ontworpen DSL's zullen een chaos creëren.
Ja, dat ben ik helemaal met Den Haan eens. Voor mij is dat ook een reden om meer van archetypes gebruik te maken. Die zijn geschreven in UML, en dus veel makkelijker te begrijpen en te integreren.
6. Niet volledig executeerbare modeltransformaties zijn een bedreiging. Ja, dat is zeker zo. He treurige gehannes met PIM en PSM in veel MDA tools is daarvan trouwens een voorbeeld (Den Haan noemt het niet).
7. Modellen kunnen meestal neit of slechts zeer moeizaam op modelnivo worden getest. Dat is natuurlijk een probleem, want de enige manier om te testen is dan; eerst alles uitgenereren (aangenomen dat dat kan), en dan testen. Maar dat maakt het natuurlijk erg onhandig om zo fouten en onvolledigheden in het model op te sporen.
8. Tooling is onvoldoende. Den Haan geeft als voorbeeld de debugger die in de modelleeromgeving meestal afwezig is. En ook hier heeft hij natuurlijk helemaal gelijk.
Den Haan's conclusie is slap:
"We’ve seen eight reasons why model-driven approaches can fail to make their promises come true. It’s not my goal to discourage you from starting with model-driven software development. I just wanted to show you the complexity of it and wanted to share some thoughts hopefully pointing you at directions helping you to overcome the complexity of MDE."
De hamvraag is natuurlijk: als die 8 risico's er inderdaad zijn (en ik denk dat Den Haan daarin ruwweg wel gelijk heeft), heeft MDE dan eigenlijk wel kans van slagen? De titel van zijn artikel suggereert dat Den Haan daarover sceptisch is, maar hij geeft zelf geen antwoord op de vraag.
En ik doe dat ook even niet, want ik kom erop terug. :)
De 8 redenen zijn ook meer 8 grote risico's, en in zijn schets daarvan heeft hij wel gelijk. Ik zal ze even nalopen.
1. De gangbare MDE-aanpakken en -tools zijn vrijwel uitsluitend gericht op het korte termijn doel van verhoging van produktiviteit voor developers: meer functiepunten per uur, en verder niks.
Ja, dat is zo, en dat is inderdaad een van de grote tekortkomingen van de gebruikelijke aanpakken. Links laten liggen dus, en richten op waar het in MDE echt over gaat (vorige week blogde ik daarover ook al).
2. in MDE concentreert men zich meestal op slechts één modelleringsdimensie. Architectuur bijvoorbeeld wordt er bij de MDA aanpak een beetje bijgefrommeld in de PSM.
Inderdaad, dat lijkt nergens op. Den Haan is hier nog veel te voorzichtig: je hebt zowel binnen het domein als binnen de weergave van de technische architectuur en implementatie verscheidene modelleringsdimensies nodig.
Naar mijn idee is dat te doen met een goede modeltransformatieaanpak, maar simpel is het niet. Bovendien: hoeveel modeldimensies moeten we aankunnen?
3. de gangbare tools richten zich op het maken van nieuwe artefacten (stukken code, getransformeerde modellen, etc) en laten de problemen van aanpassing van bestaande artefacten links liggen.
Den Haan heeft hier ongetwijfeld gelijk, maar ik denk dat hij hier de zaak wat complexer maakt dan strikt nodig is. Immers, als je afgeleide artefacten 100% kunt genereren, kun je ook zelfs voor een kleine wijziging de hele zwik van (tussen)modellen, code, enzovoort gewoon opnieuw maken. Daar zitten nadelen en beperkingen aan (zoals de veteranen uit de CBD-hoek weten), maar je komt er wel een eind mee.
4. MDE richt zich teveel op General Purpose Languages zoals UML. Dat is niet voldoende: je hebt voor deelterreinen specifieke talen nodig. Het bekende DSL-lied.
Ja, dat is zo, maar ik denk wel dat in ieder geval als het gaat om business domeinen de combinatie van "gewoon" UML, analyse patronen (archetypes) en een abstractiemechanisme waarmee specifieke modellen van meer generieke patronen kunnen worden afgeleid heel veel helpt. Je kunt dan natuurlijk zo'n analyse-patroon of een bepaalde afleiding als een DSL zien.
Zie ook hier en hier en hier.
5. Zelf ontworpen DSL's zullen een chaos creëren.
Ja, dat ben ik helemaal met Den Haan eens. Voor mij is dat ook een reden om meer van archetypes gebruik te maken. Die zijn geschreven in UML, en dus veel makkelijker te begrijpen en te integreren.
6. Niet volledig executeerbare modeltransformaties zijn een bedreiging. Ja, dat is zeker zo. He treurige gehannes met PIM en PSM in veel MDA tools is daarvan trouwens een voorbeeld (Den Haan noemt het niet).
7. Modellen kunnen meestal neit of slechts zeer moeizaam op modelnivo worden getest. Dat is natuurlijk een probleem, want de enige manier om te testen is dan; eerst alles uitgenereren (aangenomen dat dat kan), en dan testen. Maar dat maakt het natuurlijk erg onhandig om zo fouten en onvolledigheden in het model op te sporen.
8. Tooling is onvoldoende. Den Haan geeft als voorbeeld de debugger die in de modelleeromgeving meestal afwezig is. En ook hier heeft hij natuurlijk helemaal gelijk.
Den Haan's conclusie is slap:
"We’ve seen eight reasons why model-driven approaches can fail to make their promises come true. It’s not my goal to discourage you from starting with model-driven software development. I just wanted to show you the complexity of it and wanted to share some thoughts hopefully pointing you at directions helping you to overcome the complexity of MDE."
De hamvraag is natuurlijk: als die 8 risico's er inderdaad zijn (en ik denk dat Den Haan daarin ruwweg wel gelijk heeft), heeft MDE dan eigenlijk wel kans van slagen? De titel van zijn artikel suggereert dat Den Haan daarover sceptisch is, maar hij geeft zelf geen antwoord op de vraag.
En ik doe dat ook even niet, want ik kom erop terug. :)
vrijdag 8 augustus 2008
model driven engineering: waar gaat het om?
Waarom zou je model driven engineering (MDE) willen?
Volgens mij komt het in de kern neer op 2 dingen.
1. de Model-kant: "aspecten" (of eigenschappen, of gegevens, of "business-rules", of welk interessant kenmerk van een systeem dan ook) worden op slechts één plaats beschreven, en dus ook op slechts één plaats aangepast of toegevoegd. Onderhoudbaarheid, flexibiliteit etc zijn vervolgens uw deel.
Dit klinkt makkelijk, maar is het niet. Het gaat dan om het handig toepassen van een aantal "abstractie dimensies".
Horizontale abstractie: loskoppeling "separate concerns" in aparte modellen. Dus: loskoppeling verscheidene domeinapsecten, loskoppeling verscheidene architectuuraspecten, op een hoger nivo: loskoppeling domein en architectuur, enzovoort.
2. de Driven-kant: een aanpassing van een Model-aspect wordt op slechts één plaats in het ontwikkelproces gedaan. Dus in een model, of in de code, maar niet allebei. Als het op meer plaatsen gebeurt, zal al heel snel het laatste punt waar het moet in het proces (meestal de aanpassing in de code) ook de enige zijn waar het gebeurt. En dan wordt het zo goed bedachte model heel snel waardeloos.
Overigens betekent dit niet dat het aanpassingen altijd op dezelfde plaats in het proces dienen te gebeuren. Het is wat mij betreft acceptabel als een aanpassing van een business aspect in een domein model plaatsvindt, terwijl een bepaald architectonisch aspect in een stuk code (dat is dan blijkbaar het model) moet gebeuren.
Het probleem met heel veel model driven aanpakken en tools is dat men zich concentreert op punt 2, de Driven-kant van Model Driven, en dat daarbij ook nog eens wordt gedaan alsof beschrijving in een grafisch model veel beter is dan in code. Dat hoeft lang niet altijd het geval te zijn.
Hoe dan ook: als men de Model-kant niet goed voor elkaar heeft, wordt het niks. Je moet weten wat in welke modellen wordt beschreven, hoe die samenhangen, enzovoort. In de gangbare MDA-aanpakken wordt kennelijk nog steeds gedacht dat er slechts één domeinmodel nodig is, en dat de architectuur niet apart behoeft te worden gemodelleerd. Dat is onzin, en het leidt tot mislukte projecten.
Volgens mij komt het in de kern neer op 2 dingen.
1. de Model-kant: "aspecten" (of eigenschappen, of gegevens, of "business-rules", of welk interessant kenmerk van een systeem dan ook) worden op slechts één plaats beschreven, en dus ook op slechts één plaats aangepast of toegevoegd. Onderhoudbaarheid, flexibiliteit etc zijn vervolgens uw deel.
Dit klinkt makkelijk, maar is het niet. Het gaat dan om het handig toepassen van een aantal "abstractie dimensies".
Horizontale abstractie: loskoppeling "separate concerns" in aparte modellen. Dus: loskoppeling verscheidene domeinapsecten, loskoppeling verscheidene architectuuraspecten, op een hoger nivo: loskoppeling domein en architectuur, enzovoort.
2. de Driven-kant: een aanpassing van een Model-aspect wordt op slechts één plaats in het ontwikkelproces gedaan. Dus in een model, of in de code, maar niet allebei. Als het op meer plaatsen gebeurt, zal al heel snel het laatste punt waar het moet in het proces (meestal de aanpassing in de code) ook de enige zijn waar het gebeurt. En dan wordt het zo goed bedachte model heel snel waardeloos.
Overigens betekent dit niet dat het aanpassingen altijd op dezelfde plaats in het proces dienen te gebeuren. Het is wat mij betreft acceptabel als een aanpassing van een business aspect in een domein model plaatsvindt, terwijl een bepaald architectonisch aspect in een stuk code (dat is dan blijkbaar het model) moet gebeuren.
Het probleem met heel veel model driven aanpakken en tools is dat men zich concentreert op punt 2, de Driven-kant van Model Driven, en dat daarbij ook nog eens wordt gedaan alsof beschrijving in een grafisch model veel beter is dan in code. Dat hoeft lang niet altijd het geval te zijn.
Hoe dan ook: als men de Model-kant niet goed voor elkaar heeft, wordt het niks. Je moet weten wat in welke modellen wordt beschreven, hoe die samenhangen, enzovoort. In de gangbare MDA-aanpakken wordt kennelijk nog steeds gedacht dat er slechts één domeinmodel nodig is, en dat de architectuur niet apart behoeft te worden gemodelleerd. Dat is onzin, en het leidt tot mislukte projecten.
donderdag 7 augustus 2008
Applicaties in de cloud
Ars Technica heeft een verslag van een presentatie van Jeffrey Birnbaum, CTO van Merril Lynch. Hij denkt dat niet alleen data, maar ook de applicaties als zodanig in de cloud kunnen verdwijnen. Met andere woorden; ze runnen op een machine waar op dat moment ruimte is, en hoeven niet meer aan een server te worden toegewezen, laat staan dat ze op de client hoeven te draaien.
Klinkt als een goed plan, en ik denk dat je nog verder kunt gaan, door de "applicaties" op te knippen in kleinere componenten, met data en functionaliteit bij elkaar. En dan hebben we reizende objecten....
Klinkt als een goed plan, en ik denk dat je nog verder kunt gaan, door de "applicaties" op te knippen in kleinere componenten, met data en functionaliteit bij elkaar. En dan hebben we reizende objecten....
vrijdag 1 augustus 2008
Computable
Sommige van mijn stukjes zullen verschijnen in het expert-panel (over SaaS) van de Computable.
Het "Boter bij de vis"-verhaal (de vorige post op deze blog) is in iets gewijzigde vorm daar verschenen.
Compleet met foto.....
Het "Boter bij de vis"-verhaal (de vorige post op deze blog) is in iets gewijzigde vorm daar verschenen.
Compleet met foto.....
dinsdag 29 juli 2008
Boter bij de vis
Een aantal Web 2.0 bedrijven, zoals Facebook en Google, hebben ietwat tegenvallende resultaten bekendgemaakt. Als belangrijskte oorzaak wordt opgegeven dat het moeilijk blijkt de groei van de inkomsten uit advertenties vast te houden. Ik vind dat niet verbazingwekkend, en in zekere zin zelfs goed nieuws, zeker voor SaaS.
Waarom is het niet verbazingwekkend? Bij de problemen in de advertentiemarkt wordt natuurlijk gewezen naar de economie. Dat is ongetwijfeld terecht, maar er is ook een meer fundamentele oorzaak: advertenties als primaire inkomstenbron voor "Web 2.0" is eenvoudigweg op langere termijn niet vol te houden.
Oorspronkelijk waren sites als Google, Yahoo, allerhande blogs, social networks zoals Facebook een dun schilletje om de appel van de "echte" economie waarin echt geld omging. En die "echte' economie wilde maar al te graag die dunne schil gebruiken als middel om te verkopen.
Maar inmiddels is de schil veel dikker geworden, onder andere doordat veel producten die eerst in de "echte" economie zaten, en echt geld opbrachten, inmiddels digitaal en virtueel zijn geworden. Helaas voor de producenten zijn de betalingen ook virtueel geworden. Een voorbeeld is natuurlijk de muziek-industrie. Die is hard bezig uit de "echte" economie (betalade CDs) te schuiven naar de virtuele Web 2.0-economie (gratis downloads of streams).
Met andere woorden: de schil wordt dikker, en de appel wordt kleiner. En ook nog eens minder relevant, want de produkten die in de oude "echte" economie blijven, zijn veelal niet zo geschikt voor channeling via het Web. Zijn advertenties voor huizen of auto's echt zinvol op een blog over SaaS? De conclusie is onontkoombaar: de Web-economie kan voor de inkomsten niet langer leunen op de "echte" economie, maar zal op eigen benen moeten gaan staan, en zelf tot de "echte" economie moeten gaan behoren.
De consument moet dus gaan betalen voor de diensten en informatie die hij via het Web gebruikt of krijgt. Op dit moment is daarvoor de gangbare oplossing een of andere vorm van abonnement. Ik betaal een bedrag per maand, en krijg daarvoor het recht om een bepaalde dienst of informatiebron te gebruiken. Tot nog toe is dit slechts matig succevol geweest. Daarvoor zijn veel redenen, maar de belangrijkste is dat je je zo als consument te vast verbindt aan een leverancier. Immers, hoeveel abonnementen op bijvoorbeeld een nieuwssite ga je afsluiten? Eén? Twee misschien? Meer niet. Maar dat is nogal een beperking, en bovendien maakt dit het leven voor kleinere of nieuwe aanbeiders veel moeilijker. En het afsluiten van zo'n abonnement is toch een Beslissing. En Beslissingen nemen we liever niet in de vloeibare wereld van het Web.
Veel interessanter is een vorm van microbetaling, waarbij je een klein bedrag betaalt per actie (ophalen bepaalde informatie, gebruik van een dienst). Echt pay-as-you-go dus. Maar er zijn twee hinderpalen.
De eerste hinderpaal is de onwennigheid van de klant. Hoe werkt het? Is het safe? Waarom zou ik betalen als het ook gratis kan? Enzovoort. Ik denk dat als de tweede hinderpaal uit de weg is geruimd, en de aanbieders steeds meer gaan naar betaalde diensten eenvoudig omdat het anders niet meer te doen is, deze onwennigheid vanzelf verdwijnt.
De tweede hinderpaal is het betaalsysteem. De gangbare vorm van betaling op het Web is door middel van de credit card. Die gebruikt men liever niet voor betalingen aan onbekende partijen, en bovendien: het is veel te duur. Er moet dus een systeem komen waarbij je betaalt via een vertrouwde partij, die ook de mogelijkheid geeft je betalingen in te zien of te maximeren, en die voor gegroepeerde betalingen in één keer afrekent met de credit card maatschappij en zodoende de kosten laag houdt. PayPal gaat in deze richting, en het voortreffelijke Flexible Payment System (FPS) van Amazon is een nog beter voorbeeld. En ongetwijfeld komen er alternatieven (een doorontwikkeling van Google Checkout bijvoorbeeld).
Het voordeel voor SaaS wordt zo duidelijk. Het grote voordeel van SaaS is het kostenmodel. Geen grote investering meer vantevoren, kosten die min of meer gelijk op gaan met het gebruik. Maar (over het algemeen) nog wel een abonnement, en daardoor toch een Beslissing, zij het een veel kleinere dan de BESLISSING om een ERP-pekket te kopen en te implementeren. En echt pay-as-you-go is een abonnement ook niet. Als je het nauwelijks gebruikt is het nog steeds duur, en opzeggen is ook weer een Beslissing. (Hoeveel tijdschriften die u niet leest krijgt u elke maand in de brievenbus?)
Deze stand van zaken hindert de verbreiding van SaaS. De beslissing om een bepaalde SaaS-toepassing te gaan gebruiken, wordt moeilijker gemaakt door het feit dat er toch een zekere mate van (economische) lockin is, en dat daardoor alternatieven geen optie meer zijn. (Er zijn daarnaast natuurlijk ook allerhande organisatorische en technische obstakels, maar die laat ik hier buiten beschouwing.) De salescycles voor SaaS-leveranciers zijn (mede) daardoor langer en zwaarder dan men aanvankelijk verwachtte, en in ieder geval duurder dan voor het SaaS-model gewenst is.
Als onder druk van het door de hoeven zakkende advertentiemodel er inderdaad een goed werkend en goedkoop systeem voor microbetalingen tot stand komt, heeft niet alleen de consumentenmarkt daarvan voordeel, maar ook B2B SaaS. Want het wordt zo mogelijk om SaaS niet alleen via het abonnementsmodel ook via een alternatief model aan te bieden. Dat zal de verkoop van meer fijn-granulaire services te mogelijk maken. En ook guerilla-marketing wordt daardoor makkelijker, en dat drukt weer de kosten van de verkoop.
Op dit moment zit SaaS nog tussen tafellaken en servet: SaaS is goedkoper en meer "pay-as-you-go" dan pakketsoftware, maar economisch eigenlijk niet flexibel genoeg om de beloften volledig waar te kunnen maken. Voor een deel heeft dat te maken met het betaalmodel. De komst van een echt pay-as-you-go-systeem in de consumentenmarkt gaat daarin verandering brengen, en daarom zijn de tegenvallende advertentie-inkomsten van Google, Facebook, c.s. goed nieuws.
Waarom is het niet verbazingwekkend? Bij de problemen in de advertentiemarkt wordt natuurlijk gewezen naar de economie. Dat is ongetwijfeld terecht, maar er is ook een meer fundamentele oorzaak: advertenties als primaire inkomstenbron voor "Web 2.0" is eenvoudigweg op langere termijn niet vol te houden.
Oorspronkelijk waren sites als Google, Yahoo, allerhande blogs, social networks zoals Facebook een dun schilletje om de appel van de "echte" economie waarin echt geld omging. En die "echte' economie wilde maar al te graag die dunne schil gebruiken als middel om te verkopen.
Maar inmiddels is de schil veel dikker geworden, onder andere doordat veel producten die eerst in de "echte" economie zaten, en echt geld opbrachten, inmiddels digitaal en virtueel zijn geworden. Helaas voor de producenten zijn de betalingen ook virtueel geworden. Een voorbeeld is natuurlijk de muziek-industrie. Die is hard bezig uit de "echte" economie (betalade CDs) te schuiven naar de virtuele Web 2.0-economie (gratis downloads of streams).
Met andere woorden: de schil wordt dikker, en de appel wordt kleiner. En ook nog eens minder relevant, want de produkten die in de oude "echte" economie blijven, zijn veelal niet zo geschikt voor channeling via het Web. Zijn advertenties voor huizen of auto's echt zinvol op een blog over SaaS? De conclusie is onontkoombaar: de Web-economie kan voor de inkomsten niet langer leunen op de "echte" economie, maar zal op eigen benen moeten gaan staan, en zelf tot de "echte" economie moeten gaan behoren.
De consument moet dus gaan betalen voor de diensten en informatie die hij via het Web gebruikt of krijgt. Op dit moment is daarvoor de gangbare oplossing een of andere vorm van abonnement. Ik betaal een bedrag per maand, en krijg daarvoor het recht om een bepaalde dienst of informatiebron te gebruiken. Tot nog toe is dit slechts matig succevol geweest. Daarvoor zijn veel redenen, maar de belangrijkste is dat je je zo als consument te vast verbindt aan een leverancier. Immers, hoeveel abonnementen op bijvoorbeeld een nieuwssite ga je afsluiten? Eén? Twee misschien? Meer niet. Maar dat is nogal een beperking, en bovendien maakt dit het leven voor kleinere of nieuwe aanbeiders veel moeilijker. En het afsluiten van zo'n abonnement is toch een Beslissing. En Beslissingen nemen we liever niet in de vloeibare wereld van het Web.
Veel interessanter is een vorm van microbetaling, waarbij je een klein bedrag betaalt per actie (ophalen bepaalde informatie, gebruik van een dienst). Echt pay-as-you-go dus. Maar er zijn twee hinderpalen.
De eerste hinderpaal is de onwennigheid van de klant. Hoe werkt het? Is het safe? Waarom zou ik betalen als het ook gratis kan? Enzovoort. Ik denk dat als de tweede hinderpaal uit de weg is geruimd, en de aanbieders steeds meer gaan naar betaalde diensten eenvoudig omdat het anders niet meer te doen is, deze onwennigheid vanzelf verdwijnt.
De tweede hinderpaal is het betaalsysteem. De gangbare vorm van betaling op het Web is door middel van de credit card. Die gebruikt men liever niet voor betalingen aan onbekende partijen, en bovendien: het is veel te duur. Er moet dus een systeem komen waarbij je betaalt via een vertrouwde partij, die ook de mogelijkheid geeft je betalingen in te zien of te maximeren, en die voor gegroepeerde betalingen in één keer afrekent met de credit card maatschappij en zodoende de kosten laag houdt. PayPal gaat in deze richting, en het voortreffelijke Flexible Payment System (FPS) van Amazon is een nog beter voorbeeld. En ongetwijfeld komen er alternatieven (een doorontwikkeling van Google Checkout bijvoorbeeld).
Het voordeel voor SaaS wordt zo duidelijk. Het grote voordeel van SaaS is het kostenmodel. Geen grote investering meer vantevoren, kosten die min of meer gelijk op gaan met het gebruik. Maar (over het algemeen) nog wel een abonnement, en daardoor toch een Beslissing, zij het een veel kleinere dan de BESLISSING om een ERP-pekket te kopen en te implementeren. En echt pay-as-you-go is een abonnement ook niet. Als je het nauwelijks gebruikt is het nog steeds duur, en opzeggen is ook weer een Beslissing. (Hoeveel tijdschriften die u niet leest krijgt u elke maand in de brievenbus?)
Deze stand van zaken hindert de verbreiding van SaaS. De beslissing om een bepaalde SaaS-toepassing te gaan gebruiken, wordt moeilijker gemaakt door het feit dat er toch een zekere mate van (economische) lockin is, en dat daardoor alternatieven geen optie meer zijn. (Er zijn daarnaast natuurlijk ook allerhande organisatorische en technische obstakels, maar die laat ik hier buiten beschouwing.) De salescycles voor SaaS-leveranciers zijn (mede) daardoor langer en zwaarder dan men aanvankelijk verwachtte, en in ieder geval duurder dan voor het SaaS-model gewenst is.
Als onder druk van het door de hoeven zakkende advertentiemodel er inderdaad een goed werkend en goedkoop systeem voor microbetalingen tot stand komt, heeft niet alleen de consumentenmarkt daarvan voordeel, maar ook B2B SaaS. Want het wordt zo mogelijk om SaaS niet alleen via het abonnementsmodel ook via een alternatief model aan te bieden. Dat zal de verkoop van meer fijn-granulaire services te mogelijk maken. En ook guerilla-marketing wordt daardoor makkelijker, en dat drukt weer de kosten van de verkoop.
Op dit moment zit SaaS nog tussen tafellaken en servet: SaaS is goedkoper en meer "pay-as-you-go" dan pakketsoftware, maar economisch eigenlijk niet flexibel genoeg om de beloften volledig waar te kunnen maken. Voor een deel heeft dat te maken met het betaalmodel. De komst van een echt pay-as-you-go-systeem in de consumentenmarkt gaat daarin verandering brengen, en daarom zijn de tegenvallende advertentie-inkomsten van Google, Facebook, c.s. goed nieuws.
vrijdag 25 juli 2008
For whom the bell tolls...., part 3
Eerder schreef ik (hier en hier) over de problemen die leveranciers van "oude" pakket-software gaan krijgen als ze de (prijs)concurrentie van SaaS-leveranciers gaan voelen.
SAP heeft kennelijk besloten naar voren te vluchten, en bestaande klanten vanaf 1 januari 2009 meer te laten betalen voor lopende contracten. Die zijn daar natuurlijk niet blij mee, en SAP zal dat ook best hebben voorzien. Maar die klanten kunnen voorlopig geen kant uit, dus: kassa.
Alleen: het zal de overstap naar goedkopere SaaS-alternatieven (misschien wel van SAP zelf) op iets langere termijn alleen maar versnellen, maar wie dan leeft, die dan zorgt. Denken ze blijkbaar in Walldorf.
SAP heeft kennelijk besloten naar voren te vluchten, en bestaande klanten vanaf 1 januari 2009 meer te laten betalen voor lopende contracten. Die zijn daar natuurlijk niet blij mee, en SAP zal dat ook best hebben voorzien. Maar die klanten kunnen voorlopig geen kant uit, dus: kassa.
Alleen: het zal de overstap naar goedkopere SaaS-alternatieven (misschien wel van SAP zelf) op iets langere termijn alleen maar versnellen, maar wie dan leeft, die dan zorgt. Denken ze blijkbaar in Walldorf.
dinsdag 22 juli 2008
Investeringen in cloud-computing
Volgens een rapport van Goldman Sachs, waarover ComputerWorld heeft gepubliceerd, zal de werkgelegenheid in de IT dalen. Althans, volgens de geinterviewde CIO's en business executives, want daarop is het verhaal gebaseerd. Bedrijven gaan minder besteden outsourcing en aan contractwerk, en kostenbesparing dmv virtualisatie e.d. krijgt veel aandacht.
Het is allemaal niet vreemd, en perfect logisch, zeker als het economisch wat minder gaat, al vloeit uit het mindere werk in de bedrijven van de "top CIOs" niet voort dat er elders niet werk kan bijkomen.
Interessanter is de opmerking aan het eind dat de interviewees geen grote investeringen in cloud-computing, SaaS, e.d. verwachten. Men vindt dat verrassend, maar in het stuk wordt opgemerkt dat hier wel eens sprake kan zijn van een "pointy-haired boss" probleem:
"One reason for the low priorities of grid computing, open-source software and cloud computing may be that CIOs and business executives don't understand their value. "They require a technical understanding to get to their importance. I don't think C-level executives and managers have that understanding," King said."
[King is Charles King, een aangehaalde analyst.]
Inderdaad, het zou heel goed kunnen. Dit soort toplieden loopt vaak wat achter de feiten aan.
Maar er zijn nog twee andere redenen denkbaar waarom ze cloudcomputing en SaaS niet erg zien, en het dus neit als prioriteit noemen.
1. de impact van SaaS en cloudcomputing vindt (nu nog) grotendeels buiten invloedssfeer van CIOs e.d. plaats. Het gaat hier om CIO's e.d. van grote bedrijven, terwijl voor SaaS en cloudcomputing geldt dat de winst juist voor kleinere bedrijven veel groter is. Binnen grote bedrijven wordt SaaS vooral toegepast bij afdelingen en voor systemen die nou net niet bediend worden door de IT-afdeling van de CIO.
Als dit waar is, dan zijn SaaS en cloudcomputing voor die CIOs topjes van ijsbergen waarvan zij denken dat ze nog ver weg zijn.
2. SaaS en cloudcomputing vergen gezien vanuit de klant domweg niet zoveel investeringen, en daarom wordt het niet als prioriteit genoemd.
Want dat blijft natuurlijk wel waar: SaaS en cloudcomputing kunnen de kosten van "corporate IT" aanzienlijk verlagen, en dat is ook hun belangrijkste voordeel. En inderdaad, voro de werkgelegenheid in de "corporate IT" heeft dat grote gevolgen.
Voor de IT als geheel kan dat best heel anders liggen.
Het is allemaal niet vreemd, en perfect logisch, zeker als het economisch wat minder gaat, al vloeit uit het mindere werk in de bedrijven van de "top CIOs" niet voort dat er elders niet werk kan bijkomen.
Interessanter is de opmerking aan het eind dat de interviewees geen grote investeringen in cloud-computing, SaaS, e.d. verwachten. Men vindt dat verrassend, maar in het stuk wordt opgemerkt dat hier wel eens sprake kan zijn van een "pointy-haired boss" probleem:
"One reason for the low priorities of grid computing, open-source software and cloud computing may be that CIOs and business executives don't understand their value. "They require a technical understanding to get to their importance. I don't think C-level executives and managers have that understanding," King said."
[King is Charles King, een aangehaalde analyst.]
Inderdaad, het zou heel goed kunnen. Dit soort toplieden loopt vaak wat achter de feiten aan.
Maar er zijn nog twee andere redenen denkbaar waarom ze cloudcomputing en SaaS niet erg zien, en het dus neit als prioriteit noemen.
1. de impact van SaaS en cloudcomputing vindt (nu nog) grotendeels buiten invloedssfeer van CIOs e.d. plaats. Het gaat hier om CIO's e.d. van grote bedrijven, terwijl voor SaaS en cloudcomputing geldt dat de winst juist voor kleinere bedrijven veel groter is. Binnen grote bedrijven wordt SaaS vooral toegepast bij afdelingen en voor systemen die nou net niet bediend worden door de IT-afdeling van de CIO.
Als dit waar is, dan zijn SaaS en cloudcomputing voor die CIOs topjes van ijsbergen waarvan zij denken dat ze nog ver weg zijn.
2. SaaS en cloudcomputing vergen gezien vanuit de klant domweg niet zoveel investeringen, en daarom wordt het niet als prioriteit genoemd.
Want dat blijft natuurlijk wel waar: SaaS en cloudcomputing kunnen de kosten van "corporate IT" aanzienlijk verlagen, en dat is ook hun belangrijkste voordeel. En inderdaad, voro de werkgelegenheid in de "corporate IT" heeft dat grote gevolgen.
Voor de IT als geheel kan dat best heel anders liggen.
vrijdag 18 juli 2008
For whom the bell tolls.... part 2
Aardig stuk van Sarah Lacy in BusinessWeek. Strekking: de grote mastodonten van de "oude" software, zoals SAP en Microsoft, hebben grote moeite om zich een plaats te verwerven in de SaaS/cloud-wereld. En zij schrijft dat (terecht denk ik) vooral toe aan het feit dat in SaaS nu eenmaal veel minder verdiend wordt dan wat de mastodonten gewend zijn.
Oracle volgt volgens haar een andere koers: nu zoveel mogelijk het oude model uitmelken, en dan later de succesvolle SaaS=-leveranciers "cherry-picken". Ongetwijfeld zal dit het plan van Oracle zijn, maar dan nog steeds: ook dan zal Oracle merken dat de marges in SaaS en in de cloud veel smaller zijn. En ik zie niet waarom Oracle daar zoveel beter tegen zou kunnen dan SAP of Microsoft.
Twee maanden geleden postte ik:
"Dat vereist een andere manier van verkopen, een andere benadering van de klanten, en vooral ook een veel goedkopere bedrijfsvoering. En juist daar hebben bedrijven die zeer succesvol waren in het licentie-pradigma, zoals SAP en Microsoft, een probleem. Want ze verdienden geld als water, en hebben de kostenstructuur daarop afgestemd. Die kostenstructuur (salarissen, bonussen, hoofdkantoren, enzovoort, enzovoort) veranderen is heel moeilijk, ook al weet je dat het nodig is."
Dat is het probleem van SAP en Microsoft, en het wordt het probleem van Oracle.
Oracle volgt volgens haar een andere koers: nu zoveel mogelijk het oude model uitmelken, en dan later de succesvolle SaaS=-leveranciers "cherry-picken". Ongetwijfeld zal dit het plan van Oracle zijn, maar dan nog steeds: ook dan zal Oracle merken dat de marges in SaaS en in de cloud veel smaller zijn. En ik zie niet waarom Oracle daar zoveel beter tegen zou kunnen dan SAP of Microsoft.
Twee maanden geleden postte ik:
"Dat vereist een andere manier van verkopen, een andere benadering van de klanten, en vooral ook een veel goedkopere bedrijfsvoering. En juist daar hebben bedrijven die zeer succesvol waren in het licentie-pradigma, zoals SAP en Microsoft, een probleem. Want ze verdienden geld als water, en hebben de kostenstructuur daarop afgestemd. Die kostenstructuur (salarissen, bonussen, hoofdkantoren, enzovoort, enzovoort) veranderen is heel moeilijk, ook al weet je dat het nodig is."
Dat is het probleem van SAP en Microsoft, en het wordt het probleem van Oracle.
woensdag 16 juli 2008
Mark van den Brand
Dit is zo te zien een samenvatting van de inaugurale rede die Mark van den Brand gaf op 3 juli j.l. in Eindhoven.
vrijdag 11 juli 2008
REST en gedistribueerde objecten
Ik heb wat lovende reacties gekregen voor een eerdere post over REST. Dank daarvoor.
Maar ik heb ook wat misverstanden geschapen, geloof ik.
Is REST de opvolger van Java voor zover het de implementatie van het object-model betreft? Nee. REST is wat mij betreft alleen de implementatie van de structuur van het object-model: de samenhang tussen de grof-granulaire domein-objecten, en voor de communicatie tussen die objecten.
Althans: voorzover ze op het Web zijn gedistribueerd.
Dus de "binnenkant" van de objecten zal met een andere taal, Java, of Python, of Ruby, of voor mijn part Cobol, C of Erlang, worden geimplementeerd. En als de de objecten niet gedistribueerd behoeven te zijn, maar alleen maar "lokaal" in een applicatie worden gebruikt, is REST ook overbodig.
Maar ik denk wel dat die grof-granulaire objecten steeds meer (ook) als zelfstandige entiteiten op het Web beschikbaar moeten zijn, dat wel.
En ik denk ook dat REST niet het eindpunt is. Daarvoor is REST te weinig passend op wat je echt wil. Niet alleen is de "fit" met object-modellen niet 100%, maar vooral ook het feit dat het communicatie-protocol HTTP is, levert beperkingen op.
Natuurlijk is volgens de REST-adepten juist het gebruik van plain HTTP het grote voordeel, en ze hebben in veel opzichten gelijk. Maar bijvoorbeeld asynchroniteit zit niet in HTTP. Dat betekent dat als asynchrone messages nodig zijn (en dat is bijna altijd zo), dat moet worden opgelost binnen de resources of althans binnen de server die de resources beheert.
Een gestandaardiseerde abstractielaag bovenop REST, waarbij de URI-structuur in stand blijft, prettig zou zijn. Komt zo dan toch weer WS-* via de achterdeur binnen? Nee, dat is niet de bedoeling. Veel WS-* standaarden hebben op zichzelf nut, alleen: de implementatie is zeer toolgebonden, en erg ondoorzichtig.
Ik vraag me af: zou het mogelijk zijn een Erlang-achtige taal te maken die asynchroniteit inbouwt, en gewoon op HTTP is gebaseerd? Of gaat dat toch weer een lekkende abstractie worden?
Maar ik heb ook wat misverstanden geschapen, geloof ik.
Is REST de opvolger van Java voor zover het de implementatie van het object-model betreft? Nee. REST is wat mij betreft alleen de implementatie van de structuur van het object-model: de samenhang tussen de grof-granulaire domein-objecten, en voor de communicatie tussen die objecten.
Althans: voorzover ze op het Web zijn gedistribueerd.
Dus de "binnenkant" van de objecten zal met een andere taal, Java, of Python, of Ruby, of voor mijn part Cobol, C of Erlang, worden geimplementeerd. En als de de objecten niet gedistribueerd behoeven te zijn, maar alleen maar "lokaal" in een applicatie worden gebruikt, is REST ook overbodig.
Maar ik denk wel dat die grof-granulaire objecten steeds meer (ook) als zelfstandige entiteiten op het Web beschikbaar moeten zijn, dat wel.
En ik denk ook dat REST niet het eindpunt is. Daarvoor is REST te weinig passend op wat je echt wil. Niet alleen is de "fit" met object-modellen niet 100%, maar vooral ook het feit dat het communicatie-protocol HTTP is, levert beperkingen op.
Natuurlijk is volgens de REST-adepten juist het gebruik van plain HTTP het grote voordeel, en ze hebben in veel opzichten gelijk. Maar bijvoorbeeld asynchroniteit zit niet in HTTP. Dat betekent dat als asynchrone messages nodig zijn (en dat is bijna altijd zo), dat moet worden opgelost binnen de resources of althans binnen de server die de resources beheert.
Een gestandaardiseerde abstractielaag bovenop REST, waarbij de URI-structuur in stand blijft, prettig zou zijn. Komt zo dan toch weer WS-* via de achterdeur binnen? Nee, dat is niet de bedoeling. Veel WS-* standaarden hebben op zichzelf nut, alleen: de implementatie is zeer toolgebonden, en erg ondoorzichtig.
Ik vraag me af: zou het mogelijk zijn een Erlang-achtige taal te maken die asynchroniteit inbouwt, en gewoon op HTTP is gebaseerd? Of gaat dat toch weer een lekkende abstractie worden?
Representaties
Kees schrijft over REST representaties:
"Goed, het is dus de inhoud (de data) van het object, in een bepaalde
weergave. In OO-talen kan dat meestal niet in één klap zonder
tussenkomst van methods, want daar vindt men dat een object z'n data
moet afschermen en alleen via methods toegankelijk moet maken. Het is
dus zoiets als de method toString van Java. Klopt dat?"
Min of meer.
Ja, een representatie is een weergave van de resource op een of andere manier. In HTML, met plaatjes, alleen een bepaald deel van de info geselecteerd, een bepaalde volgorde, enzovoort.
En inderdaad schermt het begrip "representatie" de resource af van de buitenwereld. Strikt genomen weet je van een resource niets anders dan welke representaties eruit kunnen komen, en weet je dus ook niets van de binnenkant. (Maar dit is inderdaad wel nogal strikte theorie, omdat een netwerk van resources zelf al een sterke semantiek heeft. Als je niet weet wat een bepaalde resource voorstelt, heeft RESTful werken niet zoveel zin.)
Als je om een representatie vraagt (via de GET), roep je inderdaad een method aan, nl de GET, met eventueel parameters in de URI. Wat dat betreft is de REST-implementatie minstens zo OO als de meeste OO talen.
Te vergelijken met toString? Ja, ik denk het wel. Maar de gemiddelde GET voegt wel veel meer semantiek toe.
"Goed, het is dus de inhoud (de data) van het object, in een bepaalde
weergave. In OO-talen kan dat meestal niet in één klap zonder
tussenkomst van methods, want daar vindt men dat een object z'n data
moet afschermen en alleen via methods toegankelijk moet maken. Het is
dus zoiets als de method toString van Java. Klopt dat?"
Min of meer.
Ja, een representatie is een weergave van de resource op een of andere manier. In HTML, met plaatjes, alleen een bepaald deel van de info geselecteerd, een bepaalde volgorde, enzovoort.
En inderdaad schermt het begrip "representatie" de resource af van de buitenwereld. Strikt genomen weet je van een resource niets anders dan welke representaties eruit kunnen komen, en weet je dus ook niets van de binnenkant. (Maar dit is inderdaad wel nogal strikte theorie, omdat een netwerk van resources zelf al een sterke semantiek heeft. Als je niet weet wat een bepaalde resource voorstelt, heeft RESTful werken niet zoveel zin.)
Als je om een representatie vraagt (via de GET), roep je inderdaad een method aan, nl de GET, met eventueel parameters in de URI. Wat dat betreft is de REST-implementatie minstens zo OO als de meeste OO talen.
Te vergelijken met toString? Ja, ik denk het wel. Maar de gemiddelde GET voegt wel veel meer semantiek toe.
woensdag 9 juli 2008
Fukuyama van de automatisering
In een reactie op het verhaal over REST en OO wordt gezegd dat ik zo de "Francis Fukuyama van de automatisering" word.
:)
dinsdag 8 juli 2008
Representaties
Kees schrijft:
"Wat is een "representation" van een object? Werkt het als een referentie naar dat object, kun je het bijvoorbeeld op die manier veranderen, of is het alleen data en niet het object zelf?"
Goede vraag. Het begrip "representation" binnen REST is inderdaad wat schimmig. Het is een view op een object, maw: een set gegevens, in een bepaalde formattering. Een weergave van iets in HTML is een representatie, de verzameling van orders gesorteerd op datum ook, enzovoort.
In feite is het begrip "representation" de afscherming van de inhoud van een object binnen de context van REST. Informatie vraag je aan een resource via de GET, en wat je krijgt is (per definitie) een representation.
De representation is dus alleen data, en niet het object/resource zelf. Daarvan, of althans: van de resource, heb je de URI. Je kunt de URI kopieren, maar niet de resource zelf.
Het is ook goed om in de gaten te houden dat de begrippen "object", "message", "reference", enzovoort eigenlijk vreemd zijn aan REST. Daar gaat het over "resources", "representations", "URIs". Je kunt (zie eerdere post) wel een zinnige projectie van de OO-begrippen naar de REST-begrippen maken, maar daarmee wordt het nog niet hetzelfde.
Wel denk ik dat het zinnig is de begrippensets wat beter op elkaar te laten passen. Bijvoorbeeld: in REST gebruik je de URI zowel voor resource-identificatie als voor (in OO-termen) parameter passing. Dat kan, het heeft voordelen, maar het zijn voor elk zinnig mens wel verschillende dingen. (Het is ook wel grappig om te zien in welke bochten de REST-puristen zich wringen om deze twee dingen in essentie toch wel hetzelfde te laten zijn.) Het zou helpen als er een duidelijke conventie of desnoods standaard was welk deel van de URI locatie is, en welk deel parameter passing.
"Wat is een "representation" van een object? Werkt het als een referentie naar dat object, kun je het bijvoorbeeld op die manier veranderen, of is het alleen data en niet het object zelf?"
Goede vraag. Het begrip "representation" binnen REST is inderdaad wat schimmig. Het is een view op een object, maw: een set gegevens, in een bepaalde formattering. Een weergave van iets in HTML is een representatie, de verzameling van orders gesorteerd op datum ook, enzovoort.
In feite is het begrip "representation" de afscherming van de inhoud van een object binnen de context van REST. Informatie vraag je aan een resource via de GET, en wat je krijgt is (per definitie) een representation.
De representation is dus alleen data, en niet het object/resource zelf. Daarvan, of althans: van de resource, heb je de URI. Je kunt de URI kopieren, maar niet de resource zelf.
Het is ook goed om in de gaten te houden dat de begrippen "object", "message", "reference", enzovoort eigenlijk vreemd zijn aan REST. Daar gaat het over "resources", "representations", "URIs". Je kunt (zie eerdere post) wel een zinnige projectie van de OO-begrippen naar de REST-begrippen maken, maar daarmee wordt het nog niet hetzelfde.
Wel denk ik dat het zinnig is de begrippensets wat beter op elkaar te laten passen. Bijvoorbeeld: in REST gebruik je de URI zowel voor resource-identificatie als voor (in OO-termen) parameter passing. Dat kan, het heeft voordelen, maar het zijn voor elk zinnig mens wel verschillende dingen. (Het is ook wel grappig om te zien in welke bochten de REST-puristen zich wringen om deze twee dingen in essentie toch wel hetzelfde te laten zijn.) Het zou helpen als er een duidelijke conventie of desnoods standaard was welk deel van de URI locatie is, en welk deel parameter passing.
vrijdag 4 juli 2008
Ik rest mijn case
In de zgn. REST-SOA-discussie lopen allerlei vragen door elkaar heen: hoe makkelijk moet een protocol zijn? hoe erg is het om ingewikkelde tools, zoals ESBs, nodig te hebben? heb je bijvoorbeeld transaction awareness nodig? enzovoort.
Dat zijn allemaal interessante en ook relevante vragen, maar ik denk dat het toch vooral om iets anders gaat, namelijk de manier waarop je objecten (en daarmee semantische modellen) kunt gebruiken op het Web.
Toen zo'n 20 jaar geleden OO doorbrak, werd hoog opgegeven van de voordelen: je maakte een model in objecten van het relevante domein, je implementeerde dat in een daartoe geëigende omgeving, en het werkte. Schaalbaarheid, onderhoudbaarheid, en wat niet al waren je deel.
En dat kon dankzij het feit dat goed ontworpen objecten een unieke identiteit hadden en vindbaar waren op een unieke lokatie, ze stelden functionaliteit beschikbaar via een interface, en de interne implementatie en gegevens waren afgeschermd van de buitenwereld. Objecten waren eigenlijk zelfstandige entiteiten die elkaar kennen en met elkaar samenwerken.
Natuurlijk bleek de werkelijkheid wat prozaïscher, en kon er erg veel misgaan. Maar desondanks: als eea goed werd aangepakt, konden de beloften worden ingelost. Althans: binnen de run-time omgeving van een OO-omgeving, bijvoorbeeld een SmallTalk-image. En dus: eigenlijk slechts binnen het geheugen van een applicatie en zolangs als die applicatie loopt.
Persistentie en distributie verstoorden dus de OO-droom, en maakten het nodig om ingewikkelde oplosssinngen te bedenken, waarmee verzekerd werd dat objecten bewaard en geditribueerd konden worden, en wel op een "transparante" wijze. En dus werd er heel wat afgemapt.
Het persistentie-probleem is min of meer opgelost. Er kwamen OO-databases die het applicatiegeheugen en de "echte" database naadloos ("transparant", jazeker) in elkaar over lieten lopen. Erg mooi, en vrijwel niemand gebruikte het. Maar ook de wat meer aardse oplossing via een ORM (object relational mapping) bleek na wat vijven en zessen goed werkend te krijgen.
Het distributie-probleem bleek persistenter. :) Hoe moest de "ruimte" van objecten in één applicatie op één machine worden uitgebreid naar andere ruimtes van andere applicaties op andere machines? Met andere woorden: hoe maken we van al die ruimtes één grote ruimte?
De meest voor de hand liggende oplossingsrichting was: maak bovenop het netwerk een protocol wat ervoor zorgt dat objecten war dan ook elkaar kunnen kennen en direct boodschappen sturen. Java RMI is van deze route een voorbeeld.
Dat werkte, althans tot op zekere hoogte. Binnen een closely-knitted LAN was het netwerk stabiel genoeg om van het netwerk te kunnen abstraheren. Maar daarbuiten bleek dat een fictie: het netwerk was niet stabiel genoeg, en dan kun je het ook niet transparant maken. Bovendien waren de RMI-objecten niet echt persistent, omdat ze in feite afhankelijk waren van de applicatie waarbinnen ze bestonden. En tenslotte was de bovenop het netwerk vereiste laag dusdanig ingewikkeld dat het nooit een algemene standaard kon worden. En dat is ook niet gebeurd: RMI kun je alleen binnen de Java-architectuur gebruiken, en die is niet universeel.
Men kon er niet onderuit: het was niet mogelijk om een werkend object-netwerk te maken volledig geabstraheerd van het netwerk. Dus werd het begrip "component" (opnieuw) ingevoerd. Componenten waren entiteiten die op het netwerk draaiden, en als zodanig bekend waren, en via een functioneel interface aangeroepen konden worden.
Maar hoe verhielden de componenten zich tot de objecten?
Een eerste schot was: laat elk object, althans elk zelfstandig domeinobject, een component zijn. Maar er zijn verschrikkelijk veel domeinobjecten. Die allemaal een echte zelfstandige component maken zou veel te veel resources vergen. Immers, de functionaliteit die nodig is om iets een zelfstandige, vindbare, persistente eintiteit op een netwerk (een component dus) te maken, is fors.Dus moest er een oplossing worden bedacht waarin de object-componenten weliswaar algemeen bekend en bereikbaar waren, maar voor de standaard-component functionaliteit gebruik maakten van een soort component voedingsbodem.
De J2EE-EntityBeans waren een poging in deze richting, maar al ras bleek dat zelfs in deze aanpak veel te veel componenten ontstonden om een acceptabele performance te halen. Bovendien konden J2EE-componenten alleen goed met J2EE-componenten praten, dus van een universele ruimte was sowieso geen sprake. En vergelijkbare nadelen golden voor andere pogingen in deze richting zoals COM/DCOM.
Goed, objecten konden dus niet allemaal componenten worden. Dan maar een hybride benadering: we hebben componenten, en daarbinnen leven objecten. En we gaan een standaard ontwikkelen volgens welke componenten met elkaar, in via die route gedistribueerde objecten met elkaar, kunnen praten. En dat niet gebonden aan één talomgeving (zoals bij RMI). Dat was Corba.
Ingewikkeld? Ja, en ook nog eens slechts een standaard, nog geen implementatie. En je had er meestal dure en in ieder geval moeilijk te begrijpen tools voor nodig.
Een andere variant was: laten we het niet te ingewikkeld maken. We zien de componenten gewoon als objecten (ze hebben tenslotte al een unieke lokatie, en een interface met mooie functies, en we proberen zo'n beetje de OO-ontwerp principes voor het ontwerp van die componenten te gebruiken. Daar is weinig op tegen, en als er goede standaarden zijn of komen voor de communicatie tussen de componenten, dan heeft dit een goede kans van slagen. O ja, en heel belangrijk: we noemen het anders, dan lijkt het nieuw.
Ziedaar SOA, en dankzij XML, SOAP en de WS-* standaarden is het inderdaad een behoorlijk succes. En dankzij het Web en HTTP is de ruimte van componenten nu ook universeel.
Maar het lost het oorspronkelijke probleem niet op. Want SOA-services of -componenten zijn geen domeinobjecten, al lijken ze er een beetje op. Eigenlijk zijn we weer terug bij af: we hebben componenten (services) die elkaar kunnen vinden en met elkaar kunnen praten. Objecten bestaan wel, maar zitten binnenin de componenten. En als ee object een boodschap wil sturen aan een object in een andere component, moet eerst worden uitgezocht waar het doelobject zich eigenlijk bevindt, moet de boodschap vervolgens worden vertaald naar een serviceaanroep, moet daarbij worden aangegeven voor welk object de boodschap eigenlijk is bedoeld, en kan daarna de service-aanroep worden gedaan. En aan de andere kant moet de booschap dan weer worden uitgepakt en ontcijferd, en worden doorgestuurd naar het doelobject. Het kan wel, maar het is erg omslachtig. (Al is dat bij gebruik van MDD-technieken midner bezwaarlijk.)
Stand van zaken: we hebben eindelijk een universele ruimte, maar alleen voor componenten. Die gebruiken om echte objecten direct aan elkaar te hangen is niet gelukt, vanwege gebrek aan eenvoud, gebrek aan standaardisatie, en gebrek aan persistentie.
En toen kwam REST.
De resources van REST vormen een universele ruimte, ze zijn (uiteraard) persistent, ze zijn vindbaar en uniek dankzij de URI, het is een bestaande en zeer wijdverbreide standaard (HTTP in feite), en hij is bewezen makkelijk te gebruiken: het hele Web is erop gebaseerd.
Zouden objecten dan te mappen zijn op HTTP-resources?
Op het eerste gezicht is de mapping lastiger dan op RPC-style componenten. Objecten hebben een unieke identificatie ne locatie nodig, en dat biedt de resource inderdaad dankzij de URI. Maar niet elke via een URI te identificeren resource is een echt object, sommige zijn een "representation" van een object, in OO-termen een returnwaarde van een method.
En de REST-methods passen ook niet zonder meer op de methods in een objectmodel. Immers, REST kent slechts een beperkt aantal methods (GET, PUT, POST, DELETE zijn relevant in dit verband). De eerste drie hebben een heel strikte betekenis, en de consequentie is dat extra informatie (parameters in een method van een object) in de URI wordt gestopt. En methods die niet kunnen worden gezien als een GET, PUT of DELETE moeten via POST worden "getruct".
Vanuit OO ziet het er dus op het eerste gezicht niet zo heel goed uit. Maar als je wat beter kijkt, lijkt dat erg mee te vallen. De object-methods uit een goed ontworpen OO-domeinmodel blijken vrijwel alle zonder veel problemen te kunnen worden vertaald naar HTTP-methods.
Maar dan nog steeds: het wringt. HTTP-resources zijn brokken informatie die aan elkaar zij gerelateerd, met verscheidene representaties. Het zijn geen objecten die potentieel een zeer specifiek hebben. Resources hebben juist zoveel mogelijk een standaard-interface.
De claim van REST-voorstanders is dat dat standaard-interface juist een voordeel is. Doordat bijvoorbeeld de betekenis van GET is gedefineerd als: een GET mag een resource niet wijzigen, kunnen HTTP-servers GET-resultaten cachen. En door de simpele method + URI structuur zouden hergerbuikers makkelijker in staat zijn te snappen wat er gebeurt dan als ze bv een WSDL-file moeten lezen voor een SOA-service. Bij REST is de structuur van de resources en de informatie binnen de resources (te verkrijgen als representatie) primair.
In OO is dat van oudsher anders: daar is het functionele interface primair, en de informatie is juist geëncapsuleerd. Althans: volgens de OO-puristen. Als je kijkt naar een goed domeinmodel, dan blijkt dat veel meer een "semantic web" achtig ding te zijn, waarbij het interface helemaal niet zo'n leidende rol speelt.
(Voor de duidelijkheid: voor OO-toepassingen op een ander nivo dan de implementatie van domeinmodellen ligt dat anders, maar die worden ook niet geraakt door deze problematiek.)
En dus is het verschil met de REST/resource-oriented denkwijze helemaal niet zo groot als het op het eerste gezicht lijkt. En het voordeel van REST, namelijk dat je een universele ruimte met dingen (resources, objecten) krijgt, met unieke locaties, met de mogelijkheid daar via een standaard protocol boodschappen aan te sturen, en dat zonder dat je last hebt van het begrip component, dat voordeel is immens.
Is REST dus de toekomst? Ja, ik denk het wel. Maar we moeten nog wel uitzoeken hoe goed die mapping van OO op REST nou echt werkt, en ik denk dat er toch soort REST-standaard bovenop HTTP (bij via een nadere uitwerking van POST) nodig blijkt. Ook al is dat tegen het zere been van de REST-puristen.
Betekent dit dat "gewone SOA" ten dode is opgeschreven? Dat weet ik niet zo zeker. Voor "semantic web" achtige webservices is REST de eerste keus, maar er zijn ook webservices die andere eisen stellen. In de beruchte WS-* stack zitten een aantal zaken (bijvoorbeeld op het gebied van reliability en security) die wat lastig zijn vorm te geven in een REST-context. Het zou kunnen dat we die veel minder vaak nodig hebben dat we nu denken, maar of dat echt waar is moet nog maar blijken.
Maar er zijn zeker een hoop SOA/SOAP-etc interfaces die makkelijk via REST zouden kunnen werken, en ik denk dat we REST-facades bovenop SOA-interfaces gaan zien. Dat zal de migratie ook makkelijker maken.
Dat zijn allemaal interessante en ook relevante vragen, maar ik denk dat het toch vooral om iets anders gaat, namelijk de manier waarop je objecten (en daarmee semantische modellen) kunt gebruiken op het Web.
Toen zo'n 20 jaar geleden OO doorbrak, werd hoog opgegeven van de voordelen: je maakte een model in objecten van het relevante domein, je implementeerde dat in een daartoe geëigende omgeving, en het werkte. Schaalbaarheid, onderhoudbaarheid, en wat niet al waren je deel.
En dat kon dankzij het feit dat goed ontworpen objecten een unieke identiteit hadden en vindbaar waren op een unieke lokatie, ze stelden functionaliteit beschikbaar via een interface, en de interne implementatie en gegevens waren afgeschermd van de buitenwereld. Objecten waren eigenlijk zelfstandige entiteiten die elkaar kennen en met elkaar samenwerken.
Natuurlijk bleek de werkelijkheid wat prozaïscher, en kon er erg veel misgaan. Maar desondanks: als eea goed werd aangepakt, konden de beloften worden ingelost. Althans: binnen de run-time omgeving van een OO-omgeving, bijvoorbeeld een SmallTalk-image. En dus: eigenlijk slechts binnen het geheugen van een applicatie en zolangs als die applicatie loopt.
Persistentie en distributie verstoorden dus de OO-droom, en maakten het nodig om ingewikkelde oplosssinngen te bedenken, waarmee verzekerd werd dat objecten bewaard en geditribueerd konden worden, en wel op een "transparante" wijze. En dus werd er heel wat afgemapt.
Het persistentie-probleem is min of meer opgelost. Er kwamen OO-databases die het applicatiegeheugen en de "echte" database naadloos ("transparant", jazeker) in elkaar over lieten lopen. Erg mooi, en vrijwel niemand gebruikte het. Maar ook de wat meer aardse oplossing via een ORM (object relational mapping) bleek na wat vijven en zessen goed werkend te krijgen.
Het distributie-probleem bleek persistenter. :) Hoe moest de "ruimte" van objecten in één applicatie op één machine worden uitgebreid naar andere ruimtes van andere applicaties op andere machines? Met andere woorden: hoe maken we van al die ruimtes één grote ruimte?
De meest voor de hand liggende oplossingsrichting was: maak bovenop het netwerk een protocol wat ervoor zorgt dat objecten war dan ook elkaar kunnen kennen en direct boodschappen sturen. Java RMI is van deze route een voorbeeld.
Dat werkte, althans tot op zekere hoogte. Binnen een closely-knitted LAN was het netwerk stabiel genoeg om van het netwerk te kunnen abstraheren. Maar daarbuiten bleek dat een fictie: het netwerk was niet stabiel genoeg, en dan kun je het ook niet transparant maken. Bovendien waren de RMI-objecten niet echt persistent, omdat ze in feite afhankelijk waren van de applicatie waarbinnen ze bestonden. En tenslotte was de bovenop het netwerk vereiste laag dusdanig ingewikkeld dat het nooit een algemene standaard kon worden. En dat is ook niet gebeurd: RMI kun je alleen binnen de Java-architectuur gebruiken, en die is niet universeel.
Men kon er niet onderuit: het was niet mogelijk om een werkend object-netwerk te maken volledig geabstraheerd van het netwerk. Dus werd het begrip "component" (opnieuw) ingevoerd. Componenten waren entiteiten die op het netwerk draaiden, en als zodanig bekend waren, en via een functioneel interface aangeroepen konden worden.
Maar hoe verhielden de componenten zich tot de objecten?
Een eerste schot was: laat elk object, althans elk zelfstandig domeinobject, een component zijn. Maar er zijn verschrikkelijk veel domeinobjecten. Die allemaal een echte zelfstandige component maken zou veel te veel resources vergen. Immers, de functionaliteit die nodig is om iets een zelfstandige, vindbare, persistente eintiteit op een netwerk (een component dus) te maken, is fors.Dus moest er een oplossing worden bedacht waarin de object-componenten weliswaar algemeen bekend en bereikbaar waren, maar voor de standaard-component functionaliteit gebruik maakten van een soort component voedingsbodem.
De J2EE-EntityBeans waren een poging in deze richting, maar al ras bleek dat zelfs in deze aanpak veel te veel componenten ontstonden om een acceptabele performance te halen. Bovendien konden J2EE-componenten alleen goed met J2EE-componenten praten, dus van een universele ruimte was sowieso geen sprake. En vergelijkbare nadelen golden voor andere pogingen in deze richting zoals COM/DCOM.
Goed, objecten konden dus niet allemaal componenten worden. Dan maar een hybride benadering: we hebben componenten, en daarbinnen leven objecten. En we gaan een standaard ontwikkelen volgens welke componenten met elkaar, in via die route gedistribueerde objecten met elkaar, kunnen praten. En dat niet gebonden aan één talomgeving (zoals bij RMI). Dat was Corba.
Ingewikkeld? Ja, en ook nog eens slechts een standaard, nog geen implementatie. En je had er meestal dure en in ieder geval moeilijk te begrijpen tools voor nodig.
Een andere variant was: laten we het niet te ingewikkeld maken. We zien de componenten gewoon als objecten (ze hebben tenslotte al een unieke lokatie, en een interface met mooie functies, en we proberen zo'n beetje de OO-ontwerp principes voor het ontwerp van die componenten te gebruiken. Daar is weinig op tegen, en als er goede standaarden zijn of komen voor de communicatie tussen de componenten, dan heeft dit een goede kans van slagen. O ja, en heel belangrijk: we noemen het anders, dan lijkt het nieuw.
Ziedaar SOA, en dankzij XML, SOAP en de WS-* standaarden is het inderdaad een behoorlijk succes. En dankzij het Web en HTTP is de ruimte van componenten nu ook universeel.
Maar het lost het oorspronkelijke probleem niet op. Want SOA-services of -componenten zijn geen domeinobjecten, al lijken ze er een beetje op. Eigenlijk zijn we weer terug bij af: we hebben componenten (services) die elkaar kunnen vinden en met elkaar kunnen praten. Objecten bestaan wel, maar zitten binnenin de componenten. En als ee object een boodschap wil sturen aan een object in een andere component, moet eerst worden uitgezocht waar het doelobject zich eigenlijk bevindt, moet de boodschap vervolgens worden vertaald naar een serviceaanroep, moet daarbij worden aangegeven voor welk object de boodschap eigenlijk is bedoeld, en kan daarna de service-aanroep worden gedaan. En aan de andere kant moet de booschap dan weer worden uitgepakt en ontcijferd, en worden doorgestuurd naar het doelobject. Het kan wel, maar het is erg omslachtig. (Al is dat bij gebruik van MDD-technieken midner bezwaarlijk.)
Stand van zaken: we hebben eindelijk een universele ruimte, maar alleen voor componenten. Die gebruiken om echte objecten direct aan elkaar te hangen is niet gelukt, vanwege gebrek aan eenvoud, gebrek aan standaardisatie, en gebrek aan persistentie.
En toen kwam REST.
De resources van REST vormen een universele ruimte, ze zijn (uiteraard) persistent, ze zijn vindbaar en uniek dankzij de URI, het is een bestaande en zeer wijdverbreide standaard (HTTP in feite), en hij is bewezen makkelijk te gebruiken: het hele Web is erop gebaseerd.
Zouden objecten dan te mappen zijn op HTTP-resources?
Op het eerste gezicht is de mapping lastiger dan op RPC-style componenten. Objecten hebben een unieke identificatie ne locatie nodig, en dat biedt de resource inderdaad dankzij de URI. Maar niet elke via een URI te identificeren resource is een echt object, sommige zijn een "representation" van een object, in OO-termen een returnwaarde van een method.
En de REST-methods passen ook niet zonder meer op de methods in een objectmodel. Immers, REST kent slechts een beperkt aantal methods (GET, PUT, POST, DELETE zijn relevant in dit verband). De eerste drie hebben een heel strikte betekenis, en de consequentie is dat extra informatie (parameters in een method van een object) in de URI wordt gestopt. En methods die niet kunnen worden gezien als een GET, PUT of DELETE moeten via POST worden "getruct".
Vanuit OO ziet het er dus op het eerste gezicht niet zo heel goed uit. Maar als je wat beter kijkt, lijkt dat erg mee te vallen. De object-methods uit een goed ontworpen OO-domeinmodel blijken vrijwel alle zonder veel problemen te kunnen worden vertaald naar HTTP-methods.
Maar dan nog steeds: het wringt. HTTP-resources zijn brokken informatie die aan elkaar zij gerelateerd, met verscheidene representaties. Het zijn geen objecten die potentieel een zeer specifiek hebben. Resources hebben juist zoveel mogelijk een standaard-interface.
De claim van REST-voorstanders is dat dat standaard-interface juist een voordeel is. Doordat bijvoorbeeld de betekenis van GET is gedefineerd als: een GET mag een resource niet wijzigen, kunnen HTTP-servers GET-resultaten cachen. En door de simpele method + URI structuur zouden hergerbuikers makkelijker in staat zijn te snappen wat er gebeurt dan als ze bv een WSDL-file moeten lezen voor een SOA-service. Bij REST is de structuur van de resources en de informatie binnen de resources (te verkrijgen als representatie) primair.
In OO is dat van oudsher anders: daar is het functionele interface primair, en de informatie is juist geëncapsuleerd. Althans: volgens de OO-puristen. Als je kijkt naar een goed domeinmodel, dan blijkt dat veel meer een "semantic web" achtig ding te zijn, waarbij het interface helemaal niet zo'n leidende rol speelt.
(Voor de duidelijkheid: voor OO-toepassingen op een ander nivo dan de implementatie van domeinmodellen ligt dat anders, maar die worden ook niet geraakt door deze problematiek.)
En dus is het verschil met de REST/resource-oriented denkwijze helemaal niet zo groot als het op het eerste gezicht lijkt. En het voordeel van REST, namelijk dat je een universele ruimte met dingen (resources, objecten) krijgt, met unieke locaties, met de mogelijkheid daar via een standaard protocol boodschappen aan te sturen, en dat zonder dat je last hebt van het begrip component, dat voordeel is immens.
Is REST dus de toekomst? Ja, ik denk het wel. Maar we moeten nog wel uitzoeken hoe goed die mapping van OO op REST nou echt werkt, en ik denk dat er toch soort REST-standaard bovenop HTTP (bij via een nadere uitwerking van POST) nodig blijkt. Ook al is dat tegen het zere been van de REST-puristen.
Betekent dit dat "gewone SOA" ten dode is opgeschreven? Dat weet ik niet zo zeker. Voor "semantic web" achtige webservices is REST de eerste keus, maar er zijn ook webservices die andere eisen stellen. In de beruchte WS-* stack zitten een aantal zaken (bijvoorbeeld op het gebied van reliability en security) die wat lastig zijn vorm te geven in een REST-context. Het zou kunnen dat we die veel minder vaak nodig hebben dat we nu denken, maar of dat echt waar is moet nog maar blijken.
Maar er zijn zeker een hoop SOA/SOAP-etc interfaces die makkelijk via REST zouden kunnen werken, en ik denk dat we REST-facades bovenop SOA-interfaces gaan zien. Dat zal de migratie ook makkelijker maken.
woensdag 2 juli 2008
10 redenen om niet in cloud computing te gaan
Stacey Higginbotham geeft 10 bezwaren voor grote bedrijven om wantrouwend te zijn tov cloud computing. Ik zal ze hieronder groeperen.
1. Juridisch: security, compliance, juridische issues. Zijn de data wel veilig, waar zijn ze opgeslagen, mag dat wel, etc.
Dit zijn natuurlijk reële bezwaren, al heb ik de indruk dat ze oplosbaar zijn. Er zijn legio bedrijven die van cloud computing en SaaS gebruik maken, zonder dat de accountant, de rechter of Tjibbe Joustra een spaak in het wiel steekt. Bovendien heeft iedere mogelijke klant dezelfde vragen, en hebben de serieuzere aanbieders hier dan ook antwoorden op.
2. Technisch: betrouwbaarheid, performance.
Performance kan inderdaad een punt zijn. De latency van de cloud is hoger dan van lokale servers, dat kan niet anders. Of dat voor administratieve toepassingen een groot bezwaar is betwijfel ik, maar het punt blijft.
Betrouwbaarheid: de outage van AWS wordt steeds weer als voorbeeld gegeven, maar redelijkerwijs moet dan ook worden gekeken naar de downtime van "eigen" systemen. Is de cloud in dit opzicht minder betrouwbaar? Ik denk dat de meeste cloudservices een betrouwbaarheid halen die tenminste vergelijkbaar is met de eigen systemen.
Iets anders is de betrouwbaarheid van het netwerk. Dat is wel een bottleneck. Gedeeltelijk is dit te ondervangen door "dual carrier" te gaan, dat wil zeggen: twee zo verschillend mogelijke netwerken te gebruiken voor de verbinding met het internet. Het is opvallend dat nog zo weinig bedrijven deze voor de hand liggende voorziening gebruiken.
Maar dan nog steeds: het haalt niet alle risico's weg. Als men de cloud gaat gebruiken, moet men dan ook goed inschatten hoe lang men de cloudservice kan missen, en hoe betrouwbaar het netwerk is. Een optie is natuurlijk lokale caching (een eigen noodaggregaat als hetware), maar dat kost uiteraard geld en resources, en haalt dus een deel van het voordeel van cloud computing weg.
3. Platform en integratie: cloudplatforms zijn onderling niet zonder meer compatibel, data kunnen niet zonder meer van het ene naar het andere platform worden gebracht, enzovoort. kortom: lockin.
Dit is zeker een probleem. Hoe groot hangt af van de omvang en diversiteit van de "ecosystemen", maar het is zeker een zorg.
Er zijn wel oplossingen voor, bijvoorbeeld door een cloud platform onafhankelijk business model te gebruiken. Dat kan vervolgens worden geprojecteerd op verscheidene platforms of services. Daarmee is een data-conversie automatisch beschreven, en zijn ook de service-mismatches makkelijk te overzien. Maar het blijft makkelijker om binnen één ecosysteem te blijven.
En dan een paar rare argumenten:
4. clouds slurpen energie. Een vreemd bezwaar. Ja, datacenters vreten energie, maar ze besparen ook veel energie. De claim to fame van cloudcomputing is een grotere efficientie als het om PU-cycles en HDs gaat, en het is aannemelijk dat dat ook betekent dat ze energie-efficienter zijn. Maar in hoeverre dat zo is, is onduidelijk. En daarbij: het transport kost ook energie.
Hoe de balans is, is moeilijk te zeggen. Stacey H. verwijst naar een artikel in The Economist, maar in dat artikel wordt niets anders gezegd dan dat datacenters veel energie gebruiken. Hoe dat gebruik zich verhudt tot de besparing blijft onbesproken.
5. grote bedrijven hebben al een eigen cloud.
Als dat zo is, en ze zijn even goedkoop als externe clouds, dan moeten ze daar vooral mee doorgaan. (Al vraag ik me af of er veel bedrijven zijn met een efficiente eigen cloud.) Wel gelden voor die eigen clouds natuurlijk grotendeels dezelfde bezwaren als voor de externe clouds: betrouwbaarheid, performance, etc.
6. grote bedrijven beslissen traag, hebben een enorme bureaucratie, en de IT afdeling ligt dwars.
Ongetwijfeld, al is dit meer de vaststelling van een feit dan een bezwaar tegen cloud computing.
Het rare van het lijstje van Stacey H. is dat rijp (echte bezwaren en risico's, zoals betrouwbaarheid en platform lockin) op dezelfde lijn staan als gelegenheidsargumenten (ze slurpen energie) en onzinargumenten (IT is ertegen).
Het lijkt mij toch dat juist door al deze bezwaren, het eerste grote bedrijf in een bepaalde sector dat erin slaagt cloud computing voor zich te laten werken, waarschijnlijk een enorme voorsprong pakt op zijn concurrenten.
Eerder een reden voor de aanval dan voor de verdediging, zou je zeggen.
1. Juridisch: security, compliance, juridische issues. Zijn de data wel veilig, waar zijn ze opgeslagen, mag dat wel, etc.
Dit zijn natuurlijk reële bezwaren, al heb ik de indruk dat ze oplosbaar zijn. Er zijn legio bedrijven die van cloud computing en SaaS gebruik maken, zonder dat de accountant, de rechter of Tjibbe Joustra een spaak in het wiel steekt. Bovendien heeft iedere mogelijke klant dezelfde vragen, en hebben de serieuzere aanbieders hier dan ook antwoorden op.
2. Technisch: betrouwbaarheid, performance.
Performance kan inderdaad een punt zijn. De latency van de cloud is hoger dan van lokale servers, dat kan niet anders. Of dat voor administratieve toepassingen een groot bezwaar is betwijfel ik, maar het punt blijft.
Betrouwbaarheid: de outage van AWS wordt steeds weer als voorbeeld gegeven, maar redelijkerwijs moet dan ook worden gekeken naar de downtime van "eigen" systemen. Is de cloud in dit opzicht minder betrouwbaar? Ik denk dat de meeste cloudservices een betrouwbaarheid halen die tenminste vergelijkbaar is met de eigen systemen.
Iets anders is de betrouwbaarheid van het netwerk. Dat is wel een bottleneck. Gedeeltelijk is dit te ondervangen door "dual carrier" te gaan, dat wil zeggen: twee zo verschillend mogelijke netwerken te gebruiken voor de verbinding met het internet. Het is opvallend dat nog zo weinig bedrijven deze voor de hand liggende voorziening gebruiken.
Maar dan nog steeds: het haalt niet alle risico's weg. Als men de cloud gaat gebruiken, moet men dan ook goed inschatten hoe lang men de cloudservice kan missen, en hoe betrouwbaar het netwerk is. Een optie is natuurlijk lokale caching (een eigen noodaggregaat als hetware), maar dat kost uiteraard geld en resources, en haalt dus een deel van het voordeel van cloud computing weg.
3. Platform en integratie: cloudplatforms zijn onderling niet zonder meer compatibel, data kunnen niet zonder meer van het ene naar het andere platform worden gebracht, enzovoort. kortom: lockin.
Dit is zeker een probleem. Hoe groot hangt af van de omvang en diversiteit van de "ecosystemen", maar het is zeker een zorg.
Er zijn wel oplossingen voor, bijvoorbeeld door een cloud platform onafhankelijk business model te gebruiken. Dat kan vervolgens worden geprojecteerd op verscheidene platforms of services. Daarmee is een data-conversie automatisch beschreven, en zijn ook de service-mismatches makkelijk te overzien. Maar het blijft makkelijker om binnen één ecosysteem te blijven.
En dan een paar rare argumenten:
4. clouds slurpen energie. Een vreemd bezwaar. Ja, datacenters vreten energie, maar ze besparen ook veel energie. De claim to fame van cloudcomputing is een grotere efficientie als het om PU-cycles en HDs gaat, en het is aannemelijk dat dat ook betekent dat ze energie-efficienter zijn. Maar in hoeverre dat zo is, is onduidelijk. En daarbij: het transport kost ook energie.
Hoe de balans is, is moeilijk te zeggen. Stacey H. verwijst naar een artikel in The Economist, maar in dat artikel wordt niets anders gezegd dan dat datacenters veel energie gebruiken. Hoe dat gebruik zich verhudt tot de besparing blijft onbesproken.
5. grote bedrijven hebben al een eigen cloud.
Als dat zo is, en ze zijn even goedkoop als externe clouds, dan moeten ze daar vooral mee doorgaan. (Al vraag ik me af of er veel bedrijven zijn met een efficiente eigen cloud.) Wel gelden voor die eigen clouds natuurlijk grotendeels dezelfde bezwaren als voor de externe clouds: betrouwbaarheid, performance, etc.
6. grote bedrijven beslissen traag, hebben een enorme bureaucratie, en de IT afdeling ligt dwars.
Ongetwijfeld, al is dit meer de vaststelling van een feit dan een bezwaar tegen cloud computing.
Het rare van het lijstje van Stacey H. is dat rijp (echte bezwaren en risico's, zoals betrouwbaarheid en platform lockin) op dezelfde lijn staan als gelegenheidsargumenten (ze slurpen energie) en onzinargumenten (IT is ertegen).
Het lijkt mij toch dat juist door al deze bezwaren, het eerste grote bedrijf in een bepaalde sector dat erin slaagt cloud computing voor zich te laten werken, waarschijnlijk een enorme voorsprong pakt op zijn concurrenten.
Eerder een reden voor de aanval dan voor de verdediging, zou je zeggen.
SaaS en ERP
Vorige week reageerde Rik op mijn post over Ecosystemen als volgt:
"Je stelling over eco-systemen en integratie services (integratie out-of-the-box) kan alleen werken als bedrijven (afnemers van IT) zich conformeren aan best practices en standaard processen. En laat dat nu juist het terrein zijn waar de SAP-en van dienst groot zijn geworden!
Indien wat jij stelt juist is, is dat niet bepaald een argument voor het verdwijnen van de standaard pakketten waarmee organisaties deze dagen zijn vergeven. Waarom een orderverkingsproces van SAP vervangen door iets SaaS-erigs als dit prima werkt in SAP? Vanwege de kosten? Voor m.n. grote organisaties lijkt me dit nog onvoldoende argument."
Rik heeft natuurlijk volkomen gelijk als hij zegt dat ERP-pakket-leveranciers als SAP en verkopers van SaaS-functionaliteit op ERP-gebied te vergelijken zijn. De functionaliteit is hetzelfde, het verschil zit in de leveringsvorm en in het business-model.
Waarom zou een bedrijf willen overstappen van een pakket naar een SaaS-oplossing, als de functionaliteit toch ongeveer hetzelfde is?
Het belangrijkste argument: prijs. SaaS is in potentie veel geodkoper. Het gaat daarbij niet alleen om de kosten van de services vs. de kosten van de licentie, maar ook om de bijkomende kosten van on-premise computing: hardware, beheer, stroom, etc, etc.
Voor een bedrijf dat al een ERP-oplossing heeft draaien, zal dit niet onmiddellijk interessant zijn. Immers, een groot deel van de kosten van het pakket zijn al gemaakt, en overschakelen naar een SaaS-oplossing kost ook weer geld en energie.
Maar dat is anders voor bedrijven die nog niet een ERP systeem hebben (in het MKB bv), en bedrijven die voor een grote upgrade of vervanging van hun huidige ERP-pakket staan. Dan wordt SaaS wel een serieus alternatief.
Daar komt nog iets bij.
Waarom zijn grote bedrijven groot? Vooral mdat ze schaalvoordelen hebben. Een van de belangrijkste is dat een groot bedrijf zich inderdaad een SAP-implementatie kan veroorloven, en daarmee allerlei efficiency-effecten kan bereiken die voor kleinere concurrenten niet zijn weggelegd.
Maar als een SaaS-oplossing voor veel minder geld, veel minder risico en meer flexibiliteit vrijwel dezelfde functionaliteit levert, is dat voordeel weg. Er zal voor de grotere bedrijven opeens een reeks van (veel) kleinere concurrenten ontstaan, die vergelijkbare produkten en diensten leveren tegen een lagere prijs.
Als dat gebeurt, zullen veel bedrijven moeten kiezen: het model van hun nieuwe concurrenten overnemen (zelfde kostenstructuur, zelfde SaaS-oplossingen), of de extra mogelijkheden van het bestaande ERP-systeem uitnutten, en zodoende een voorsprong op de nieuwe concurrenten scheppen.
In het eerste geval zie je de ERP-functionaliteit als een commodity. Standaard, bij gelijke lwaliteit zo goedkoop mogelijk inkopen. In het tweede geval zie je in de ERP-toepassing iets wat een strategisch voordeel kan bieden.
Maar ik vraag me af of dat laatste vaak gaat lukken, zeker met een standaardpakket. Ik denk dat ERP-functionaliteit een commodity is of wordt, en dan komt het neer op de goedkoopste oplossing. En dat zal SaaS blijken te zijn.
"Je stelling over eco-systemen en integratie services (integratie out-of-the-box) kan alleen werken als bedrijven (afnemers van IT) zich conformeren aan best practices en standaard processen. En laat dat nu juist het terrein zijn waar de SAP-en van dienst groot zijn geworden!
Indien wat jij stelt juist is, is dat niet bepaald een argument voor het verdwijnen van de standaard pakketten waarmee organisaties deze dagen zijn vergeven. Waarom een orderverkingsproces van SAP vervangen door iets SaaS-erigs als dit prima werkt in SAP? Vanwege de kosten? Voor m.n. grote organisaties lijkt me dit nog onvoldoende argument."
Rik heeft natuurlijk volkomen gelijk als hij zegt dat ERP-pakket-leveranciers als SAP en verkopers van SaaS-functionaliteit op ERP-gebied te vergelijken zijn. De functionaliteit is hetzelfde, het verschil zit in de leveringsvorm en in het business-model.
Waarom zou een bedrijf willen overstappen van een pakket naar een SaaS-oplossing, als de functionaliteit toch ongeveer hetzelfde is?
Het belangrijkste argument: prijs. SaaS is in potentie veel geodkoper. Het gaat daarbij niet alleen om de kosten van de services vs. de kosten van de licentie, maar ook om de bijkomende kosten van on-premise computing: hardware, beheer, stroom, etc, etc.
Voor een bedrijf dat al een ERP-oplossing heeft draaien, zal dit niet onmiddellijk interessant zijn. Immers, een groot deel van de kosten van het pakket zijn al gemaakt, en overschakelen naar een SaaS-oplossing kost ook weer geld en energie.
Maar dat is anders voor bedrijven die nog niet een ERP systeem hebben (in het MKB bv), en bedrijven die voor een grote upgrade of vervanging van hun huidige ERP-pakket staan. Dan wordt SaaS wel een serieus alternatief.
Daar komt nog iets bij.
Waarom zijn grote bedrijven groot? Vooral mdat ze schaalvoordelen hebben. Een van de belangrijkste is dat een groot bedrijf zich inderdaad een SAP-implementatie kan veroorloven, en daarmee allerlei efficiency-effecten kan bereiken die voor kleinere concurrenten niet zijn weggelegd.
Maar als een SaaS-oplossing voor veel minder geld, veel minder risico en meer flexibiliteit vrijwel dezelfde functionaliteit levert, is dat voordeel weg. Er zal voor de grotere bedrijven opeens een reeks van (veel) kleinere concurrenten ontstaan, die vergelijkbare produkten en diensten leveren tegen een lagere prijs.
Als dat gebeurt, zullen veel bedrijven moeten kiezen: het model van hun nieuwe concurrenten overnemen (zelfde kostenstructuur, zelfde SaaS-oplossingen), of de extra mogelijkheden van het bestaande ERP-systeem uitnutten, en zodoende een voorsprong op de nieuwe concurrenten scheppen.
In het eerste geval zie je de ERP-functionaliteit als een commodity. Standaard, bij gelijke lwaliteit zo goedkoop mogelijk inkopen. In het tweede geval zie je in de ERP-toepassing iets wat een strategisch voordeel kan bieden.
Maar ik vraag me af of dat laatste vaak gaat lukken, zeker met een standaardpakket. Ik denk dat ERP-functionaliteit een commodity is of wordt, en dan komt het neer op de goedkoopste oplossing. En dat zal SaaS blijken te zijn.
maandag 30 juni 2008
Digitale Darjeeling
Beetje OT, maar wel een erg leuk verhaal over de eerste computer in een bedrijf.
donderdag 26 juni 2008
Hier is het weerbericht
Cloudstatus meet de status van cloud-services. Op dit moment alleen Amozon services, maar als ik het goed begrijp heeft men ook het plan andere cloud-services toe te voegen.
Eigenlijk wel handig.
Eigenlijk wel handig.
maandag 23 juni 2008
Te optimistisch?
Het kantoor wordt verbouwd, en er moet dus worden opgeruimd. Daarbij loop ik door een stapel oude nummers van Software Release. En in het nummer van december 1996 tref ik een artikel van mezelf aan, waarin wordt voorspeld dat we componenten niet meer gaan kopen of bouwen, maar als component via het internet gebruiken, en daarvoor huur (zouden we nu noemen: pay-as-you-go) betalen. Het stuk gaat over componenten, en niet over services, maar dat is natuurlijk hetzelfde: SaaS dus.
Verder wordt ook het punt gemaakt dat door pay-as-you-go hergebruik een groot deel van de copyright en intellectueel -eigendom-problematiek wordt vermeden.
De laatste zin is echter in zekere zin het meest interessant: "Ben ik te optimistisch?"
Het is natuurlijk leuk om achteraf gelijk te krijgen, maar het heeft wel een tijd geduurd. Als in 1996 die logica al zo onontkoombaar was, waarom is SaaS dan niet eerder doorgebroken? of was die logica toch niet zo onontkoombaar?
Gedachten hierover?
Verder wordt ook het punt gemaakt dat door pay-as-you-go hergebruik een groot deel van de copyright en intellectueel -eigendom-problematiek wordt vermeden.
De laatste zin is echter in zekere zin het meest interessant: "Ben ik te optimistisch?"
Het is natuurlijk leuk om achteraf gelijk te krijgen, maar het heeft wel een tijd geduurd. Als in 1996 die logica al zo onontkoombaar was, waarom is SaaS dan niet eerder doorgebroken? of was die logica toch niet zo onontkoombaar?
Gedachten hierover?
maandag 16 juni 2008
Ecosystemen, integratie en softwarehouses
Afgelopen week heb ik de SIIA On Demand conferentie in Amsterdam bezocht.
Twee kreten kwamen vaak terug: "ecosystem" en "integration". Die hebben met elkaar te maken, maar laten we beginnen met integratie.
Bij integratie op het gebied van SaaS gaat het eigenlijk om drie soorten integratie:
1. integratie van SaaS-services onderling in het user-interface. Een vorm daarvan is de bekende mashup, waarbij in het user-interface enkele services (bijvoorbeeld een routeplanner en Buienradar) worden samengevoegd.
2. integratie van SaaS-services met eigen (legacy-)software (zoals ooit ontwikkelde maatwerksystemen) of met gekochte pakketten (zoals SAP of Office).
3. integratie van SaaS-services "aan de achterkant", bijvoorbeeld een factureringservice van Salesforce.com, de betaalservice FPS van Amazon en een boekhoudservice van Business ByDesign (de uitgestelde SaaS-variant van SAP).
Door IT-ers wordt de eerste vorm (user-interface mashups) niet erg interessant gevonden. Immers, business-processen spelen geen rol bij Buienradar, dus dit is leuk voor fröbelende webdesigners en andere dameskappers, maar voor serieuze IT-ers is het niet van belang. (Ik denk dat dit een misvatting is, maar dat doet er nu niet zoveel toe.)
De tweede en derde vorm van integratie lijken vanuit het perspectief van de softwareontwikkeling en de IT-sector erg op elkaar. In beide gevallen moet data geconverteerd worden, moeten services worden aangeroepen, enzovoort. En inderdaad: tussen de koppeling van als service beschikbare legacy software en een SaaS-service enerzijds en tussen twee SaaS-services anderzijds bestaat geen verschil. Tenminste: vanuit technisch perspectief.
En dus hebben de softwarehouses zichzelf weer eens opnieuw uitgevonden, en proclameert men dat men voortaan SaaS-services gaat integreren, dat de klanten daar erg veel behoefte aan hebben, en dat dit in feite vrijwel net zo veel werk met zich meebrengt als traditionele systeemontwikkeling.
Op korte termijn hebben ze hierin ongetwijfeld gelijk. Maar op wat langere termijn geloof ik er niks van. Waarom niet?
1. het grote voordeel van SaaS is het "functionaliteit-uit-de-muur"-effect. Standaardfucntionaliteit wordt gebruikt in de aangeboden vorm, en daardoor zijn de kosten van een fractie van die van zelf ontwikkelde en beheerde software. Bovendien hoeft er geen voorinvestering in de vorm van ontwikkelkosten, de aanschaf van een licentie of de aanschaf van servers betaald te worden.
Maar als je ten behoeve van die spotgoedkope SaaS-functionaliteit weer een hoop integratie-scripts en dergelijke moet gaan maken en onderhouden omdat anders de legacy niet meer werkt, schiet je jezelf in de voet. Want dat is weer gewoon maatwerk: hoge kosten, en in feite lock-in. Dit is niet een argument tegen SaaS, maar tegen legacy.
De tweede vorm van integratie (SaaS-legacy) moet dus tot een minimum worden beperkt: zo weinig mogelijk, zo simpel mogelijk. Ja, de softwarehouses hebben gelijk: integratie van SaaS met legacy is duur. Maar nee: dat zal (op iets langere termijn tenminste) niet leiden tot meer werk, maar tot vervroegde uitfasering van legacy-software.
2.voor de integratie van SaaS-services met elkaar zijn drie varianten waarneembaar.
a. ad hoc integratie van SaaS-services. De gebruiker van de klant integreert de SaaS-services met elkaar, op de manier zoals hij ze nodig heeft. Deze aanpak heeft uiteraard dezelfde nadelen als legacy-SaaS-integratie, en zal dan ook een kort leven beschoren zijn, en worden verdrongen door de volgende twee ontwikkelingen.
b. de "ecosystems" (het tweede buzzword van de conferentie): op de "grote platformen" zoals Salesforce.com en Amazon's AWS ontstaan een reeks van applicaties die gebruik maken van het platform en van elkaar om allerlei geïntegreerde functionaliteit aan de klant aan te bieden. Salesforce doet dat expliciet via Force.com, Amazon doet het impliciet door stapje voor stapje de voorwaarden voor het ontstaan van zo'n ecosysteem te scheppen. En Google doet iets dergelijks, en biedt via de AppEngine ook de mogelijkheid om het platform als ontwikkelplatform te gebruiken.
c. de integratie-services. Dat zijn in feite SaaS-toepassingen die SaaS-services van diverse pluimage en diverse platforms combineren en integreren. SaaSaaS dus. Een voorbeeld hiervan is RunMyProcess, en een ander DreamFactory (hoewel dat strikt genomen geen SaaS-service is, maar een te downloaden applicatie). Er wordt dan een soort virtueel ecosysteem gecreëerd. (Maar dat ecosysteem was toch al virtueel? Hmmmm.......)
Ik denk dat de varianten b en c van de SaaS-integratie in elkaar over zullen lopen. Vanuit de consument zal het niet veel uitmaken, zolang hij zijn doelen maar haalt: lage kosten, laag risico, geen lock-in. Variant a moet vermeden worden.
Vanuit het gezichtspunt van een softwarehouse zijn legacy-SaaS-integratie en SaaS-SaaS-integratie vrijwel hetzelfde. Maar vanuit het gezichtspunt van de klant, het SaaS-consumerende bedrijf, zijn het dus twee totaal verschillende zaken. De eerste vorm van integratie hangt al snel als een molensteen om de nek van de klant, omdat ie de nadelen van SaaS met de nadelen van een eigen IT-functie combineert. De tweede vorm van integratie maakt SaaS makkelijker en goedkoper bruikbaar.
Het zou kunnen dat bij de SaaS-SaaS-integratie een kans ligt voor de softwarehouses, zeker als het om de ad hoc integratie gaat. Maar die zal snel worden verdrongen door de ecosystemen en de integratieservices. En die zijn moeilijker te leveren door de softwarehouses. Ik denk dat, voorzover de softwarehouses nu leven van het verhuren van capaciteit, ze hiertoe niet in staat zullen zijn. O, technisch kunnen ze het wel. Maar het business-model is totaal anders, en daarnaar toe overschakelen is waarschijnlijk net zo'n probleem als het overschakelen naar SaaS is voor bedrijven als SAP en Oracle.
Maar hoe zit het dan met de befaamde semantische mismatch? Gaat al dat geïntegreer wel zo makkelijk? "Begrijpen" die services elkaar dan zonder meer? Nee. Die semantische mismatch is er inderdaad nog steeds. Maar er zijn enkele ontwikkelingen die er wellicht voor zorgen dat dit probleem kleiner wordt. (Hierover binnenkort.)
Is er dan niks meer te doen voor de softwarehouses? Zeker wel. Om van SaaS gebruik te kunnen maken moeten ze weten hoe hun bedrijfsmodel mapt op de modellen van de SaaS-aanbieders. Ze moeten weten hoe en waar in hun business-processen gebruik gemaakt kan worden van welke SaaS-services. En ook de aanbieders van SaaS zullen IT-kennis nodig hebben. En er zij natuurlijk ook toepassingen die (nog) niet als SaaS beschikbaar of bruikbaar zijn.
Het idee dat dat er voor de functionaliteit die door SaaS-aanbieders goed wordt afgedekt, een krachtige IT-functie bij de klanten blijft, is een illusie. En ook integratie zal niet het werkterrein van de softwarehouses blijken, tenzij ze kans zien zich om te vormen tot SaaS-aanbieder. Maar dat is heel moeilijk.
Twee kreten kwamen vaak terug: "ecosystem" en "integration". Die hebben met elkaar te maken, maar laten we beginnen met integratie.
Bij integratie op het gebied van SaaS gaat het eigenlijk om drie soorten integratie:
1. integratie van SaaS-services onderling in het user-interface. Een vorm daarvan is de bekende mashup, waarbij in het user-interface enkele services (bijvoorbeeld een routeplanner en Buienradar) worden samengevoegd.
2. integratie van SaaS-services met eigen (legacy-)software (zoals ooit ontwikkelde maatwerksystemen) of met gekochte pakketten (zoals SAP of Office).
3. integratie van SaaS-services "aan de achterkant", bijvoorbeeld een factureringservice van Salesforce.com, de betaalservice FPS van Amazon en een boekhoudservice van Business ByDesign (de uitgestelde SaaS-variant van SAP).
Door IT-ers wordt de eerste vorm (user-interface mashups) niet erg interessant gevonden. Immers, business-processen spelen geen rol bij Buienradar, dus dit is leuk voor fröbelende webdesigners en andere dameskappers, maar voor serieuze IT-ers is het niet van belang. (Ik denk dat dit een misvatting is, maar dat doet er nu niet zoveel toe.)
De tweede en derde vorm van integratie lijken vanuit het perspectief van de softwareontwikkeling en de IT-sector erg op elkaar. In beide gevallen moet data geconverteerd worden, moeten services worden aangeroepen, enzovoort. En inderdaad: tussen de koppeling van als service beschikbare legacy software en een SaaS-service enerzijds en tussen twee SaaS-services anderzijds bestaat geen verschil. Tenminste: vanuit technisch perspectief.
En dus hebben de softwarehouses zichzelf weer eens opnieuw uitgevonden, en proclameert men dat men voortaan SaaS-services gaat integreren, dat de klanten daar erg veel behoefte aan hebben, en dat dit in feite vrijwel net zo veel werk met zich meebrengt als traditionele systeemontwikkeling.
Op korte termijn hebben ze hierin ongetwijfeld gelijk. Maar op wat langere termijn geloof ik er niks van. Waarom niet?
1. het grote voordeel van SaaS is het "functionaliteit-uit-de-muur"-effect. Standaardfucntionaliteit wordt gebruikt in de aangeboden vorm, en daardoor zijn de kosten van een fractie van die van zelf ontwikkelde en beheerde software. Bovendien hoeft er geen voorinvestering in de vorm van ontwikkelkosten, de aanschaf van een licentie of de aanschaf van servers betaald te worden.
Maar als je ten behoeve van die spotgoedkope SaaS-functionaliteit weer een hoop integratie-scripts en dergelijke moet gaan maken en onderhouden omdat anders de legacy niet meer werkt, schiet je jezelf in de voet. Want dat is weer gewoon maatwerk: hoge kosten, en in feite lock-in. Dit is niet een argument tegen SaaS, maar tegen legacy.
De tweede vorm van integratie (SaaS-legacy) moet dus tot een minimum worden beperkt: zo weinig mogelijk, zo simpel mogelijk. Ja, de softwarehouses hebben gelijk: integratie van SaaS met legacy is duur. Maar nee: dat zal (op iets langere termijn tenminste) niet leiden tot meer werk, maar tot vervroegde uitfasering van legacy-software.
2.voor de integratie van SaaS-services met elkaar zijn drie varianten waarneembaar.
a. ad hoc integratie van SaaS-services. De gebruiker van de klant integreert de SaaS-services met elkaar, op de manier zoals hij ze nodig heeft. Deze aanpak heeft uiteraard dezelfde nadelen als legacy-SaaS-integratie, en zal dan ook een kort leven beschoren zijn, en worden verdrongen door de volgende twee ontwikkelingen.
b. de "ecosystems" (het tweede buzzword van de conferentie): op de "grote platformen" zoals Salesforce.com en Amazon's AWS ontstaan een reeks van applicaties die gebruik maken van het platform en van elkaar om allerlei geïntegreerde functionaliteit aan de klant aan te bieden. Salesforce doet dat expliciet via Force.com, Amazon doet het impliciet door stapje voor stapje de voorwaarden voor het ontstaan van zo'n ecosysteem te scheppen. En Google doet iets dergelijks, en biedt via de AppEngine ook de mogelijkheid om het platform als ontwikkelplatform te gebruiken.
c. de integratie-services. Dat zijn in feite SaaS-toepassingen die SaaS-services van diverse pluimage en diverse platforms combineren en integreren. SaaSaaS dus. Een voorbeeld hiervan is RunMyProcess, en een ander DreamFactory (hoewel dat strikt genomen geen SaaS-service is, maar een te downloaden applicatie). Er wordt dan een soort virtueel ecosysteem gecreëerd. (Maar dat ecosysteem was toch al virtueel? Hmmmm.......)
Ik denk dat de varianten b en c van de SaaS-integratie in elkaar over zullen lopen. Vanuit de consument zal het niet veel uitmaken, zolang hij zijn doelen maar haalt: lage kosten, laag risico, geen lock-in. Variant a moet vermeden worden.
Vanuit het gezichtspunt van een softwarehouse zijn legacy-SaaS-integratie en SaaS-SaaS-integratie vrijwel hetzelfde. Maar vanuit het gezichtspunt van de klant, het SaaS-consumerende bedrijf, zijn het dus twee totaal verschillende zaken. De eerste vorm van integratie hangt al snel als een molensteen om de nek van de klant, omdat ie de nadelen van SaaS met de nadelen van een eigen IT-functie combineert. De tweede vorm van integratie maakt SaaS makkelijker en goedkoper bruikbaar.
Het zou kunnen dat bij de SaaS-SaaS-integratie een kans ligt voor de softwarehouses, zeker als het om de ad hoc integratie gaat. Maar die zal snel worden verdrongen door de ecosystemen en de integratieservices. En die zijn moeilijker te leveren door de softwarehouses. Ik denk dat, voorzover de softwarehouses nu leven van het verhuren van capaciteit, ze hiertoe niet in staat zullen zijn. O, technisch kunnen ze het wel. Maar het business-model is totaal anders, en daarnaar toe overschakelen is waarschijnlijk net zo'n probleem als het overschakelen naar SaaS is voor bedrijven als SAP en Oracle.
Maar hoe zit het dan met de befaamde semantische mismatch? Gaat al dat geïntegreer wel zo makkelijk? "Begrijpen" die services elkaar dan zonder meer? Nee. Die semantische mismatch is er inderdaad nog steeds. Maar er zijn enkele ontwikkelingen die er wellicht voor zorgen dat dit probleem kleiner wordt. (Hierover binnenkort.)
Is er dan niks meer te doen voor de softwarehouses? Zeker wel. Om van SaaS gebruik te kunnen maken moeten ze weten hoe hun bedrijfsmodel mapt op de modellen van de SaaS-aanbieders. Ze moeten weten hoe en waar in hun business-processen gebruik gemaakt kan worden van welke SaaS-services. En ook de aanbieders van SaaS zullen IT-kennis nodig hebben. En er zij natuurlijk ook toepassingen die (nog) niet als SaaS beschikbaar of bruikbaar zijn.
Het idee dat dat er voor de functionaliteit die door SaaS-aanbieders goed wordt afgedekt, een krachtige IT-functie bij de klanten blijft, is een illusie. En ook integratie zal niet het werkterrein van de softwarehouses blijken, tenzij ze kans zien zich om te vormen tot SaaS-aanbieder. Maar dat is heel moeilijk.
vrijdag 6 juni 2008
Krugman zegt iets zinnigs
Paul Krugman schrijft voor de eerste keer sinds jaren een column waarin de Republikeinen in het algemeen en Bush in het bijzonder niet de schuld krijgen, en het is gelijk een goed stuk.
Over de consequenties van digitalisering, de briljantie van de Amazon Kindle.
Over de consequenties van digitalisering, de briljantie van de Amazon Kindle.
maandag 2 juni 2008
maandag 19 mei 2008
McKinsey over SaaS
McKinsey heeft een rapport over SaaS gepubliceerd. Goed verhaal, strekking is: SaaS is heel snel bezig een grote factor in de IT-markt te worden.
Dat is natuurlijk niets nieuws, maar het is toch altijd prettig te horen.
Interessant is wel de indeling die McKinsey maakt van de SaaS-markt. Zij zien de volgende niveaus:
1. Managed hosting platforms, zoals IBM en OpSource.
2. Cloud computing, zoals AWS/EC2 en Google.
3. Development in de cloud, zoals via Bungee Labs en Coghead
4. "Application-led" platforms, zoals Salesforce.com.
Dat is een zinnige indeling, en ze constateren dan dat er een verschil in volwassenheid (maturity) zit tussen die platforms.
Managed hosting is het meest volwassen, gevolgd door de "application-led" platforms, cloud computing en tenslotte development in de cloud. En McKinsey constateert dan dat ook de volgorde is waarin bedrijven aangeven op korte termijn iets met SaaS te willen doen. (blz. 8). Managed hosting wordt interessant gevonden door 32 % van de respondenten, develment in de cloud door 7 %.
Het rapport stelt dan dat dat te maken heeft met de volwassenheid, en zegt vervolgens:
"For both cloud computing and general development platforms, the issue is
maturity. Especially with general development platforms, customers are still
coming to terms with the value proposition, and have no signifi cant real-world
examples from which to draw. Their success will depend on time, increased
familiarity, and the emergence of proven success in the marketplace."
Ja, inderdaad. Maar wat McKinsey hier niet zegt, in ieder geval expliciet, is dat de geringe belangstelling voor development in de cloud ook kan komen doordat dat strijdig is met het belangrijkste argument voor SaaS gezien vanuit het SaaS-consumerende bedrijf.
Immers, de grap is dat de SaaS-consument zijn functionaliteit koopt, en niet meer zelf ontwikkelt en beheert. Daaruit vloeien de voordelen van SaaS voort. Waarom zou je dan zelf willen ontwikkelen, ook al is het in de cloud? Moet een "gewoon" bedrijf dat wel willen?
Ik denk het niet. Cloud development is een erg interessante ontwikkeling, maar voor IT-ers. Het maakt het mogelijk voor IT-bedrijven om snel software te ontwikkelen, en die direc te deployen op een platform als Salesforce.com of Amazon, en vervolgens als service te verkopen. En dat zal de software-markt ingrijpende veranderen.
Maar voor "gewone" bedrijven (dwz: bedrijven wier kernactiviteit niet IT is) is dat niet interessant. Dat zou ook wel eens de geringe belangstelling kunnen verklaren.
Dat is natuurlijk niets nieuws, maar het is toch altijd prettig te horen.
Interessant is wel de indeling die McKinsey maakt van de SaaS-markt. Zij zien de volgende niveaus:
1. Managed hosting platforms, zoals IBM en OpSource.
2. Cloud computing, zoals AWS/EC2 en Google.
3. Development in de cloud, zoals via Bungee Labs en Coghead
4. "Application-led" platforms, zoals Salesforce.com.
Dat is een zinnige indeling, en ze constateren dan dat er een verschil in volwassenheid (maturity) zit tussen die platforms.
Managed hosting is het meest volwassen, gevolgd door de "application-led" platforms, cloud computing en tenslotte development in de cloud. En McKinsey constateert dan dat ook de volgorde is waarin bedrijven aangeven op korte termijn iets met SaaS te willen doen. (blz. 8). Managed hosting wordt interessant gevonden door 32 % van de respondenten, develment in de cloud door 7 %.
Het rapport stelt dan dat dat te maken heeft met de volwassenheid, en zegt vervolgens:
"For both cloud computing and general development platforms, the issue is
maturity. Especially with general development platforms, customers are still
coming to terms with the value proposition, and have no signifi cant real-world
examples from which to draw. Their success will depend on time, increased
familiarity, and the emergence of proven success in the marketplace."
Ja, inderdaad. Maar wat McKinsey hier niet zegt, in ieder geval expliciet, is dat de geringe belangstelling voor development in de cloud ook kan komen doordat dat strijdig is met het belangrijkste argument voor SaaS gezien vanuit het SaaS-consumerende bedrijf.
Immers, de grap is dat de SaaS-consument zijn functionaliteit koopt, en niet meer zelf ontwikkelt en beheert. Daaruit vloeien de voordelen van SaaS voort. Waarom zou je dan zelf willen ontwikkelen, ook al is het in de cloud? Moet een "gewoon" bedrijf dat wel willen?
Ik denk het niet. Cloud development is een erg interessante ontwikkeling, maar voor IT-ers. Het maakt het mogelijk voor IT-bedrijven om snel software te ontwikkelen, en die direc te deployen op een platform als Salesforce.com of Amazon, en vervolgens als service te verkopen. En dat zal de software-markt ingrijpende veranderen.
Maar voor "gewone" bedrijven (dwz: bedrijven wier kernactiviteit niet IT is) is dat niet interessant. Dat zou ook wel eens de geringe belangstelling kunnen verklaren.
vrijdag 16 mei 2008
For whom the bell tolls...
Vorig jaar introduceerde SAP Business ByDesign, de SaaS-versie van SAP. Ik was daar nogal enthousiast over, want ik verwachtte daar veel van. Later nuanceerde ik dat, vanwege twijfel aan het vermogen van bestaande software-leveranciers, die leven van de forse inkomensstromen die licenties en "onderhoud" opleveren, om zich aan het veel magerder SaaS-dieet aan te passen.
Inmiddels kondigt SAP aan dat zowel de ontwikkeling als de uitrol in de markt van ByDesign trager gaat en zal gaan dan verwacht en gepland. En ondertussen gaat de concurrentie, zoals Salesforce en Workday, verder.
De uitdagingen waarvoor software ontwikkelende bedrijven als SAP, Microsoft, Oracle, en vele kleinere broeders zich gesteld zien door de ontwikkeling van SaaS zijn gigantisch. Ze zullen meemoeten met SaaS, maar dat houdt in ieder geval 2 dingen in.
1. ze moeten een totaal nieuwe versie van hun produkt ontwikkelen, met een ander platform, andere technologie, een andere denkwijze, enzovoort. Dat is al moeilijk genoeg, en menig software-leverancier is niet in staat gebleken om deze stap te maken.
2. in het geval van SaaS komt daar nog bij dat het business model anders is. De inkomsten komen niet uit dure, en van tevoren betaalde, licenties en uit onderhoud, maar uitsluitend uit pay as you go gebruiksvergoedingen. De inkomsten komen later binnen, het totaalbedrag wat aan een klant kan worden verdiend is veel lager, en de klant kan ook nog eens makkelijker van je af.
Dat vereist een andere manier van verkopen, een andere benadering van de klanten, en vooral ook een veel goedkopere bedrijfsvoering. En juist daar hebben bedrijven die zeer succesvol waren in het licentie-pradigma, zoals SAP en Microsoft, een probleem. Want ze verdienden geld als water, en hebben de kostenstructuur daarop afgestemd. Die kostenstructuur (salarissen, bonussen, hoofdkantoren, enzovoort, enzovoort) veranderen is heel moeilijk, ook al weet je dat het nodig is.
Kleinere, minder winstgevende concurrenten hebben het makkelijker. De omschakeling is voor hen minder groot, juist omdat ze minder winst maakten onder het licentie-paradigma.
En het ironische is dat zowel SAP als Microsoft vroeg en goed hebben ingezien uit welke hoek de wind waaide. Microsoft realiseerde zich uitstekend dat SaaS een bedreiging vormt voor vooral Office en dergelijke applicaties, en SAP is ook al vroeg begonnen met SaaS-achtige varianten, en vorig jaar dan met een heuse SaaS-versie.
Maar ondanks de visie en de goede wil, zou het heel goed kunnen dat ze het niet gaan redden. Helemaal ter ziele gaan, dat zal wel niet gebeuren. Waarschijnlijker is dat ze "fuseren" met een partij die het wel redt in de nieuwe markt, of dat ze worden opgesplitst in kleinere eenheden, of zoiets.
De grote tijd van Microsoft, SAP en ook Oracle is voorbij. Het is juist voor de reuzen uit het software-licentie-tijdperk te moeilijk goed aan te passen. (Zie ook onder: dinosauriërs.)
Natuurlijk, er zijn eerder bedrijven geweest die dergelijke paradigma-verschuivingen hebben overleefd. IBM natuurlijk, en bv ook Apple, HP en Sun. Maar die bedrijven hebben allemaal gemeen dat ze (ook) hardware produceerden. Voor bedrijven die zich alleen maar met software bezighouden, is het veel moelijker. En juist eerder succes wordt dan een blok aan het been.
Inmiddels kondigt SAP aan dat zowel de ontwikkeling als de uitrol in de markt van ByDesign trager gaat en zal gaan dan verwacht en gepland. En ondertussen gaat de concurrentie, zoals Salesforce en Workday, verder.
De uitdagingen waarvoor software ontwikkelende bedrijven als SAP, Microsoft, Oracle, en vele kleinere broeders zich gesteld zien door de ontwikkeling van SaaS zijn gigantisch. Ze zullen meemoeten met SaaS, maar dat houdt in ieder geval 2 dingen in.
1. ze moeten een totaal nieuwe versie van hun produkt ontwikkelen, met een ander platform, andere technologie, een andere denkwijze, enzovoort. Dat is al moeilijk genoeg, en menig software-leverancier is niet in staat gebleken om deze stap te maken.
2. in het geval van SaaS komt daar nog bij dat het business model anders is. De inkomsten komen niet uit dure, en van tevoren betaalde, licenties en uit onderhoud, maar uitsluitend uit pay as you go gebruiksvergoedingen. De inkomsten komen later binnen, het totaalbedrag wat aan een klant kan worden verdiend is veel lager, en de klant kan ook nog eens makkelijker van je af.
Dat vereist een andere manier van verkopen, een andere benadering van de klanten, en vooral ook een veel goedkopere bedrijfsvoering. En juist daar hebben bedrijven die zeer succesvol waren in het licentie-pradigma, zoals SAP en Microsoft, een probleem. Want ze verdienden geld als water, en hebben de kostenstructuur daarop afgestemd. Die kostenstructuur (salarissen, bonussen, hoofdkantoren, enzovoort, enzovoort) veranderen is heel moeilijk, ook al weet je dat het nodig is.
Kleinere, minder winstgevende concurrenten hebben het makkelijker. De omschakeling is voor hen minder groot, juist omdat ze minder winst maakten onder het licentie-paradigma.
En het ironische is dat zowel SAP als Microsoft vroeg en goed hebben ingezien uit welke hoek de wind waaide. Microsoft realiseerde zich uitstekend dat SaaS een bedreiging vormt voor vooral Office en dergelijke applicaties, en SAP is ook al vroeg begonnen met SaaS-achtige varianten, en vorig jaar dan met een heuse SaaS-versie.
Maar ondanks de visie en de goede wil, zou het heel goed kunnen dat ze het niet gaan redden. Helemaal ter ziele gaan, dat zal wel niet gebeuren. Waarschijnlijker is dat ze "fuseren" met een partij die het wel redt in de nieuwe markt, of dat ze worden opgesplitst in kleinere eenheden, of zoiets.
De grote tijd van Microsoft, SAP en ook Oracle is voorbij. Het is juist voor de reuzen uit het software-licentie-tijdperk te moeilijk goed aan te passen. (Zie ook onder: dinosauriërs.)
Natuurlijk, er zijn eerder bedrijven geweest die dergelijke paradigma-verschuivingen hebben overleefd. IBM natuurlijk, en bv ook Apple, HP en Sun. Maar die bedrijven hebben allemaal gemeen dat ze (ook) hardware produceerden. Voor bedrijven die zich alleen maar met software bezighouden, is het veel moelijker. En juist eerder succes wordt dan een blok aan het been.
vrijdag 25 april 2008
donderdag 17 april 2008
App Engine op EC2
Men heeft het voro mekaar gekregen om Google's App Engine te laten draaien op Amazon's EC2....
dinsdag 8 april 2008
Daar is Google
Daar is ie dan: het applicatieplatform App Engine van Google (ruwweg de evenknie van EC2 van Amazon en Force van Salesforce.com).
Opzet is iets anders. Ik moet er nog naar kijken.
Opzet is iets anders. Ik moet er nog naar kijken.
donderdag 3 april 2008
Werkelijkheid
De werkelijkheid volgens Michael Nygard.
De conclusie: "Commerce companies underperform their potential" is duidelijk.
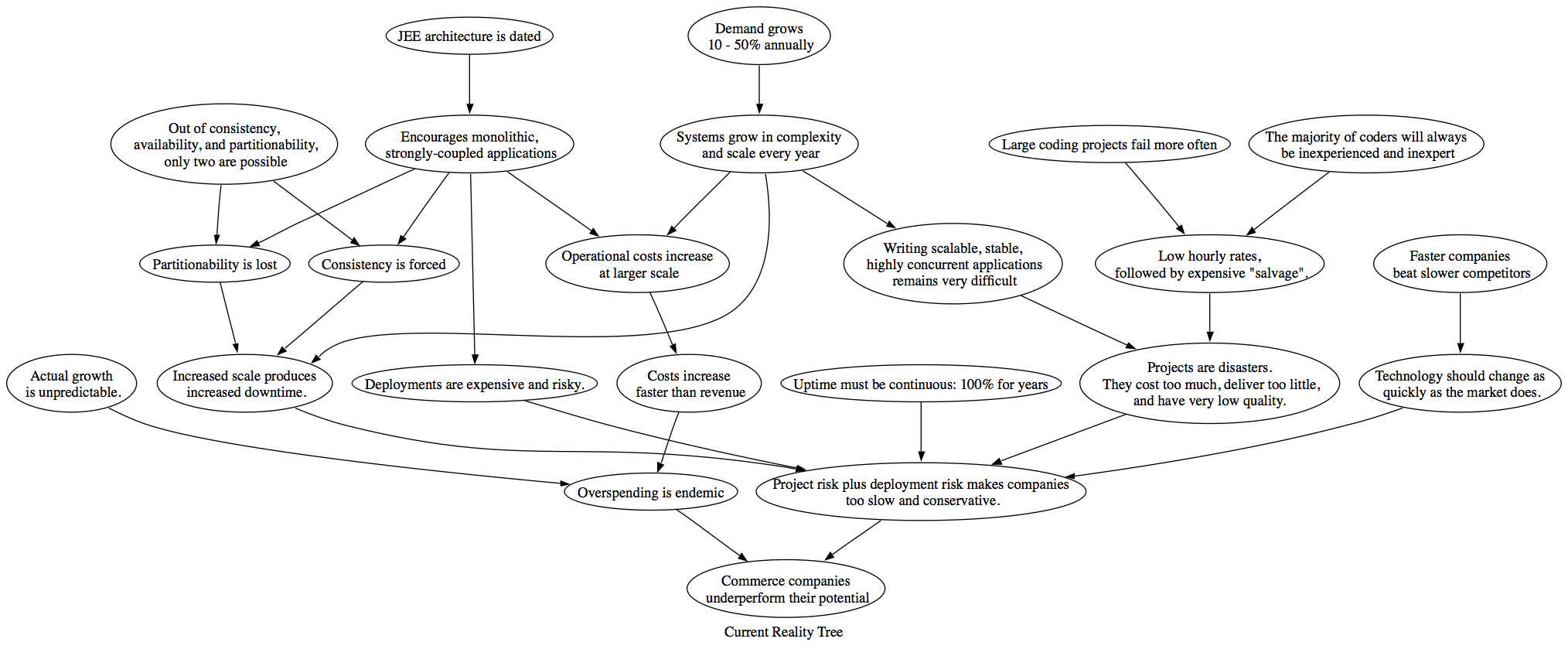{kind=link}
De conclusie: "Commerce companies underperform their potential" is duidelijk.
woensdag 2 april 2008
containers
Voor de aardigheid: over de datacenter containers van Microsoft.
"We're looking at using containers inside our future data centers. One of the things we like about them is we can take a bunch of servers and look at the output of that box and look at the power it draws. At the end of the day, we can determine, "What is the IT productivity of that unit? How many search queries were executed per box? How many emails sent or stored?" You can get into some really interesting metrics. A lot of people say you can't look at the productivity of a data center, but if you compartmentalize it -- not as small as the server level, but at some chunk in between -- you can measure productivity."
Fascinerend.
"We're looking at using containers inside our future data centers. One of the things we like about them is we can take a bunch of servers and look at the output of that box and look at the power it draws. At the end of the day, we can determine, "What is the IT productivity of that unit? How many search queries were executed per box? How many emails sent or stored?" You can get into some really interesting metrics. A lot of people say you can't look at the productivity of a data center, but if you compartmentalize it -- not as small as the server level, but at some chunk in between -- you can measure productivity."
Fascinerend.
vrijdag 21 maart 2008
JaBoWS
Nick Malik is tegen JaBoWS: Just another Bunch of WebServices. Leuke post:
"Tools + existing processes = JaBOWS"
Ik betwijfel of ik zijn enthousiasme voor Enterprise SOA helemaa kan delen, maar hier heeft ie wel gelijk in.
"Tools + existing processes = JaBOWS"
Ik betwijfel of ik zijn enthousiasme voor Enterprise SOA helemaa kan delen, maar hier heeft ie wel gelijk in.
Tilkov over REST
Aardig stuk van Stefan Tilkov op InfoQ, met een weerlegging van gangbare argumenten waarom REST niet goed bruikbaar zou zijn voor business services.
Vooral het stukje over transacties en REST is raak, wat mij betreft (punt 6). Tilkov zegt in essentie: inderdaad, met REST is het nauwelijks mogelijk over verscheidene REST services een atomaire transactie te maken. Met WS-AT etc kan dat in theorie wel, maar dan zijn die webservices wel erg strak gekoppeld, en het is waarschijnlijk organisatorisch niet mogelijk, laat staan wenselijk. (Atomaire transacties over grenzen van bedrijven heen? Hoezo loose coupling?)
Het is eigenlijk gewoon slecht design.
Vooral het stukje over transacties en REST is raak, wat mij betreft (punt 6). Tilkov zegt in essentie: inderdaad, met REST is het nauwelijks mogelijk over verscheidene REST services een atomaire transactie te maken. Met WS-AT etc kan dat in theorie wel, maar dan zijn die webservices wel erg strak gekoppeld, en het is waarschijnlijk organisatorisch niet mogelijk, laat staan wenselijk. (Atomaire transacties over grenzen van bedrijven heen? Hoezo loose coupling?)
Het is eigenlijk gewoon slecht design.
woensdag 5 maart 2008
REST en de datakoppeling
Eerder schreef ik over de verdediging van de RESTful architectuur door Steve Vinoski.
In dit artikel gaat Steve Vinoski in op het argument dat de standaardisatie van REST interfaces weliswaar standaardisatie op interface nivo oplevert, maar dat het probleem vervolgens wordt verplaatst naar de applicaties, waar de data die met de HTTP-call meekomen, moeten worden geprojecteerd op de "echte" datastructuren.
De RPC/SOAP/WS-*-route probeert die "echte' datastructuren tot een standaard te maken over webservices en componenten heen. Op die manier wordt getracht het Web 'transparant' te maken voro (object-georiënteerde) programmatuur.
Vinoski's argumentatie komt neer op het volgende:
1. RPC/SOAP/WS-* bestrijdt het minder urgente probleem. Wat je nodig hebt voor Web-computing is een protocol wat het mogelijk maakt rekening te houden met schaalbaarheid, latency, caching, etc. REST/HTTP doet dat, door de standaardisatie van methods (GET, PUT, etc), RPC/SOAP/WS-* niet door de proprietary methods.
2. De voordelen van data-standaardisatie werken niet op het Web. Binnen één programma gaat dat wel goed, maar de problemen beginnen al bij een paar componenten die data-structuren delen. Bij deling van data-definties over het Web, over de grenzen van bedrijven en systemen heen, is het een illusie te denken dat er geen vertaling naar de "echte; structuren hoeft plaats te vinden.
3. Juist het feit dat REST het netwerk NIET transparant maakt, maakt REST ontwikkeling makkelijker en robuuster. REST gebruikt de grenzen tussen client en server expliciet: de client krijgt van de server een representatie, en houdt zelf zijn state bij. Dat is duidelijk, helder, makkelijk te bouwen, en robuust.
Ik vind het verhaal van Vinoski overtuigend, in ieder geval waar het gaat om ontwikkeling voor het Web. Binnen de muren van een bedrijf ligt het genuanceerder, maar hoe lang nog zullen we services maken waarvan we zeker weten dat ze alleen in de context van het eigen bedrijf worden gebruikt?
Wel één kanntekening: Vinoski zegt eigenlijk: laten we niet proberen één standaard datastructuur voor bv Employee te hanteren, want dat lukt toch niet. OK. Maar als twee systemen door middel van een webservice communiceren over een Employee, moet wel duidelijk zijn wat een Employee is, wat de betekenis van de attributen is, enzovoort.
Er moet op semantisch gebied dus wel degelijk een overeenstemming zijn, ook als die er op technisch gebied niet is. Vinoski mompelt wat over metadata, maar mompelen lost dit natuurlijk niet op.
Voor het goed werken van webservices inderdaad geen gemeenschappelijk datamodel nodig, laat staan overeenstemming over de technische datastructuren, maar wel een gedeeld semantisch model. Dat is natuurlijk bijna hetzelfde als een gedeeld data- of object-model. Wil dat nou zeggen dat we eerst maar een wereldwijd semantisch model moeten gaan zitten maken, voordat we met het Web en SaaS aan de gang kunnen?
Nee, natuurlijk niet. Zo moeilijk is die semantiek niet, en ik denk dat dat gedeelde model nu al aan het ontstaan is. En als het er eenmaal is, zou je er ook in je interfaces gebruik van kunnen maken.
Een soort semantisch resource-model. Heerlijk......
In dit artikel gaat Steve Vinoski in op het argument dat de standaardisatie van REST interfaces weliswaar standaardisatie op interface nivo oplevert, maar dat het probleem vervolgens wordt verplaatst naar de applicaties, waar de data die met de HTTP-call meekomen, moeten worden geprojecteerd op de "echte" datastructuren.
De RPC/SOAP/WS-*-route probeert die "echte' datastructuren tot een standaard te maken over webservices en componenten heen. Op die manier wordt getracht het Web 'transparant' te maken voro (object-georiënteerde) programmatuur.
Vinoski's argumentatie komt neer op het volgende:
1. RPC/SOAP/WS-* bestrijdt het minder urgente probleem. Wat je nodig hebt voor Web-computing is een protocol wat het mogelijk maakt rekening te houden met schaalbaarheid, latency, caching, etc. REST/HTTP doet dat, door de standaardisatie van methods (GET, PUT, etc), RPC/SOAP/WS-* niet door de proprietary methods.
2. De voordelen van data-standaardisatie werken niet op het Web. Binnen één programma gaat dat wel goed, maar de problemen beginnen al bij een paar componenten die data-structuren delen. Bij deling van data-definties over het Web, over de grenzen van bedrijven en systemen heen, is het een illusie te denken dat er geen vertaling naar de "echte; structuren hoeft plaats te vinden.
3. Juist het feit dat REST het netwerk NIET transparant maakt, maakt REST ontwikkeling makkelijker en robuuster. REST gebruikt de grenzen tussen client en server expliciet: de client krijgt van de server een representatie, en houdt zelf zijn state bij. Dat is duidelijk, helder, makkelijk te bouwen, en robuust.
Ik vind het verhaal van Vinoski overtuigend, in ieder geval waar het gaat om ontwikkeling voor het Web. Binnen de muren van een bedrijf ligt het genuanceerder, maar hoe lang nog zullen we services maken waarvan we zeker weten dat ze alleen in de context van het eigen bedrijf worden gebruikt?
Wel één kanntekening: Vinoski zegt eigenlijk: laten we niet proberen één standaard datastructuur voor bv Employee te hanteren, want dat lukt toch niet. OK. Maar als twee systemen door middel van een webservice communiceren over een Employee, moet wel duidelijk zijn wat een Employee is, wat de betekenis van de attributen is, enzovoort.
Er moet op semantisch gebied dus wel degelijk een overeenstemming zijn, ook als die er op technisch gebied niet is. Vinoski mompelt wat over metadata, maar mompelen lost dit natuurlijk niet op.
Voor het goed werken van webservices inderdaad geen gemeenschappelijk datamodel nodig, laat staan overeenstemming over de technische datastructuren, maar wel een gedeeld semantisch model. Dat is natuurlijk bijna hetzelfde als een gedeeld data- of object-model. Wil dat nou zeggen dat we eerst maar een wereldwijd semantisch model moeten gaan zitten maken, voordat we met het Web en SaaS aan de gang kunnen?
Nee, natuurlijk niet. Zo moeilijk is die semantiek niet, en ik denk dat dat gedeelde model nu al aan het ontstaan is. En als het er eenmaal is, zou je er ook in je interfaces gebruik van kunnen maken.
Een soort semantisch resource-model. Heerlijk......
Abonneren op:
Posts (Atom)